Geometric Distance Metrics
1. Euclidean Distance (L2 Norm)
The Euclidean distance is the most widely used distance metric in machine learning, especially in K-means clustering. It calculates the straight-line distance between two data points in vector space.
👉 Euclidean Distance is like like measuring with a ruler
Formula for 'n' dimensions
For two points
Component Breakdown:
and : Coordinates of the two points and in -dimensional space : Summation over all dimensions (features) : Squared difference between corresponding coordinates (ensures positive values) : Square root gives actual distance (otherwise it's squared Euclidean distance)
Visual Representation in 2D:
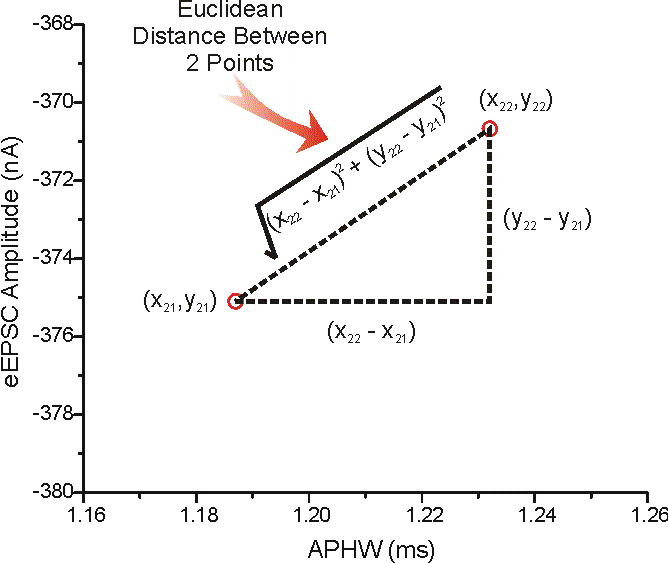
Example in 2D:
👉 In K-Means: Point
represents the cluster centroid, and we minimize the sum of squared Euclidean distances
When to Use:
- Features are continuous and on similar scales
- Data is relatively normally distributed
- All features have equal importance
- You need intuitive, geometric distance
Advantages:
- ✅ Intuitive and geometrically meaningful
- ✅ Directly optimized in K-Means
- ✅ Works well with compact, spherical clusters
Disadvantages:
- ❌ Sensitive to scale: Features with larger ranges dominate the distance
- ❌ Curse of dimensionality: Becomes less meaningful in very high dimensions
- ❌ Sensitive to outliers: Squared differences amplify large deviations
- ❌ Assumes feature independence: Doesn't account for correlations
Practical Tips:
- Always standardize/normalize features before using Euclidean distance
- Consider using Mahalanobis distance if features are correlated
- Use Manhattan distance if you want to reduce outlier sensitivity
❗ What’s wrong with using Euclidean Distance for Multivariate data?
Euclidean distance does not account for correlations among features
1. Euclidean Distance Ignores Correlation:
Euclidean distance only measures the straight-line distance between two points, without considering relationships between dimensions (features). However, in real-world datasets, features are often correlated or dependent on one another (e.g., height and weight, or income and spending habits).
2. Misleading Interpretation in Correlated Data
When features are positively or negatively correlated, data points form an elliptical distribution rather than a spherical one. In such cases, Euclidean distance assumes the points are distributed equally in all directions, leading to misleading distance measurements.
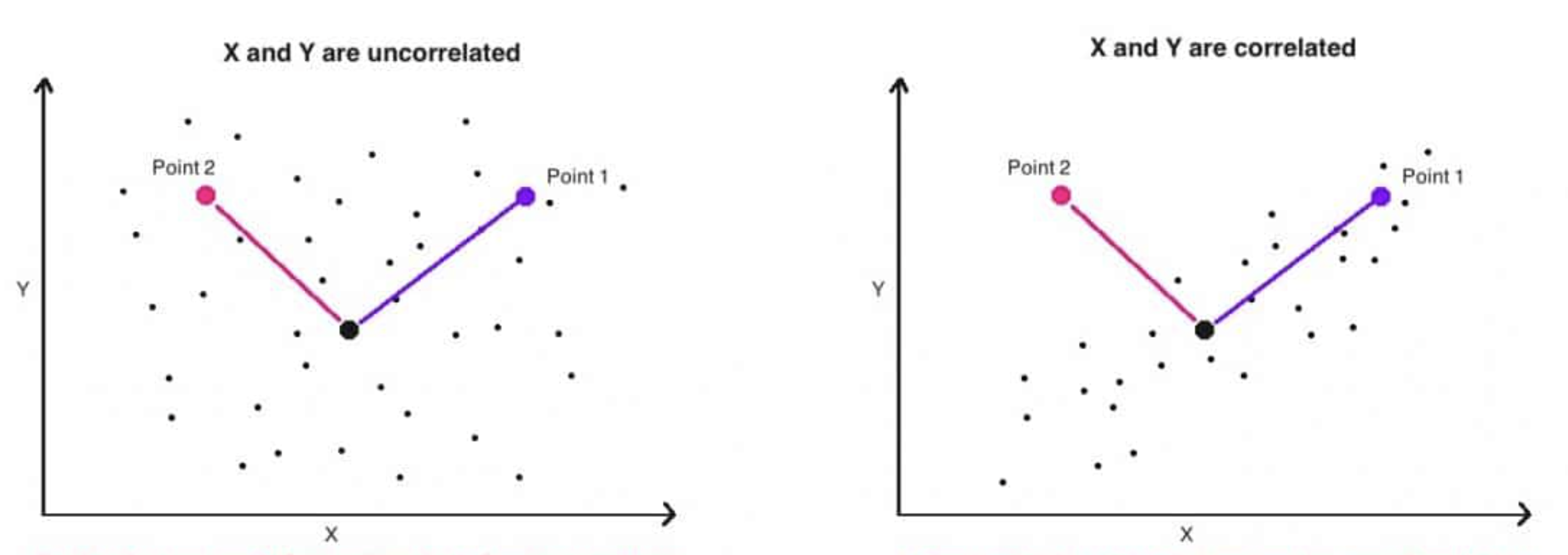
Illustration of Correlated Data
-
Uncorrelated Data (Left Plot)
When Point 1 and Point 2 are uncorrelated (points are distributed uniformly in all directions): The Euclidean distance is effective because it directly measures the proximity of a point to the cluster's centroid. -
Correlated Data (Right Plot)
When Point 1 and Point 2 are correlated (e.g., points tend to form an elliptic cluster):- Both Point 1 (inside the cluster) and Point 2 (outlier) can have identical Euclidean distances to the centroid.
- Point 1 (purple) aligns with the direction of the cluster (along the ellipse's major axis).
- Point 2 (pink) deviates significantly from the cluster because it goes against the natural direction of the data variance.
Despite its deviation, Euclidean distance cannot capture this, making Point 2 look just as close to the cluster as Point 1.
- Both Point 1 (inside the cluster) and Point 2 (outlier) can have identical Euclidean distances to the centroid.
Why Does This Happen?
Euclidean distance ignores the distribution of other points in the dataset. It only considers the distance between two individual points and doesn't account for how the rest of the points vary. Essentially:
- It assumes the data is spherically symmetric (same variance in all directions).
- It ignores the spread and correlation structure of the data, which are critical in identifying clusters or determining whether a point is an outlier.
The Solution: Use Mahalanobis Distance
The Mahalanobis Distance is a more robust alternative for measuring the distance of a point from a cluster when dealing with correlated data. It considers the distribution of the entire dataset.
2. Manhattan Distance (L1 Norm)
The Manhattan Distance (also called Taxicab Distance, City Block Distance, or L1 norm) measures the distance between two points by summing the absolute differences of their coordinates. It mimics navigating a grid-like city street layout where you can only move horizontally or vertically.
Formula for 'n' dimension
For two points
Component Breakdown:
: Absolute difference (no squaring, unlike Euclidean) : Sum over all dimensions - No square root needed (simpler computation)
Example in 2D:
Visual Comparison (2D example):
- Euclidean:
(diagonal line) - Manhattan:
(grid path)
When to Use:
- Features are on different scales (more robust than Euclidean)
- Data has outliers (less sensitive than Euclidean)
- Grid-like or discrete data structures
- You want to reduce the impact of large differences in any single dimension
Advantages:
- ✅ Less sensitive to outliers than Euclidean
- ✅ Faster to compute (no squaring or square root)
- ✅ More robust when features have different scales
- ✅ Natural for grid-based problems
Disadvantages:
- ❌ Less intuitive than Euclidean distance
- ❌ Not differentiable at zero (problematic for some optimization algorithms)
- ❌ May overestimate distances in high dimensions
Applications:
- Machine Learning: KNN, K-Medians clustering, LASSO regression (L1 regularization)
- Robotics/Pathfinding: A* algorithm on grid maps
- Image Processing: Comparing pixel intensities, image histograms
- Recommendation Systems: Similarity with categorical or ordinal features
3. Chebyshev Distance
Chebyshev distance (or
It assumes the moment can occur in any direction including diagnols.
This distance is especially useful in grid-based systems like chessboards or pathfinding in games where diagonal movement is allowed.
Formula
For points
Component Breakdown:
: Absolute difference (no squaring, unlike Euclidean) : Sum over all dimensions - No square root needed (simpler computation)
- Maximum of all Absolute difference
Visual Example in 2D
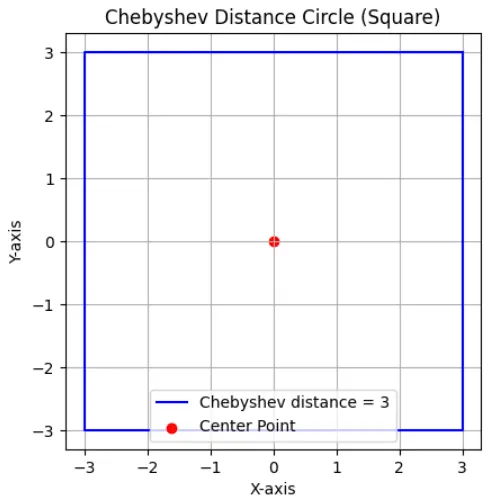
Example in 2D
Consider 2 points:
The plot shows a square centered at (0,0) representing all points exactly 3 units away by Chebyshev distance.
Advantages:
- ✅ Very fast to compute: Only need to find maximum, no summation or square roots
- ✅ Intuitive for grid-based problems: Natural for chessboard and warehouse movements
- ✅ Focuses on bottleneck: Identifies the limiting dimension
- ✅ Memory efficient: Only need to track one value (the max)
Disadvantages:
- ❌ Ignores small differences: Only the largest dimension matters, losing other information
- ❌ Poor for clustering: Not suitable for most ML algorithms like K-Means
- ❌ Less intuitive in continuous space: Works better for discrete grids
- ❌ Sensitive to single outlier dimension: One extreme coordinate can dominate
- ❌ Limited ML applications: Rarely used in standard clustering/classification
Applications:
- Game AI & Robotics:
- Chess king movement, pathfinding with diagonal moves
- Grid-based robot navigation where diagonal movement has equal cost
- Logistics & Operations:
- Warehouse optimization (slowest worker determines completion time)
- Scheduling problems (bottleneck identification)
- Image Processing:
- Pixel neighborhood analysis (8-connectivity)
- Maximum color channel difference detection
- Quality Control:
- Manufacturing tolerance checks (worst-case dimension)
- Identifying the most deviant measurement
4. Minkowski Distance (Generalized Lp Norm)
Minkowski distance is a generalized metric used to calculate the distance between two points in
K-NN)
Formula
For two points
Special Cases:
: Manhattan Distance (L1 norm) : Euclidean Distance (L2 norm) : Chebyshev Distance (maximum absolute difference):
Example (
: (Manhattan) : (Euclidean) : : (Chebyshev)
When to Use:
- Experiment with different
values to find what works best for your data - Higher
values give more weight to larger differences - Lower
values are more robust to outliers
Visualization:
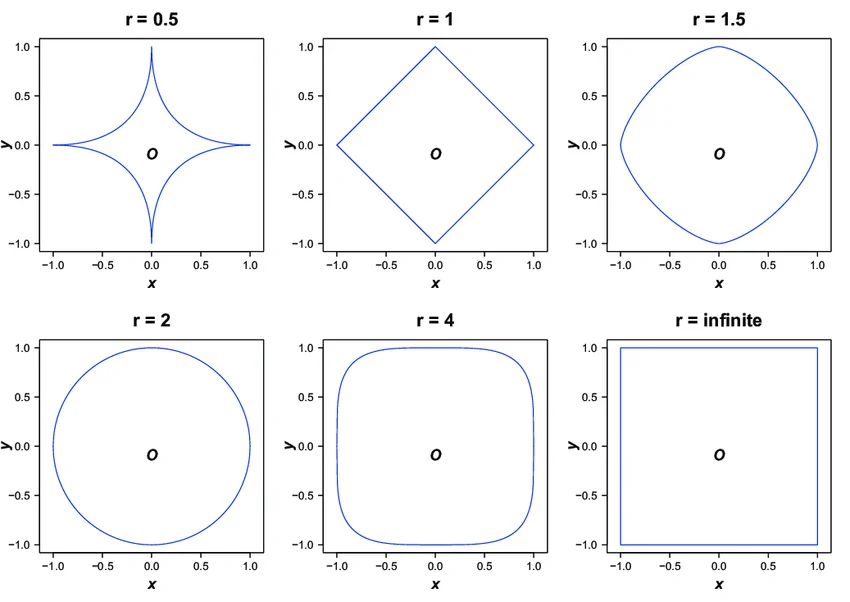
➢ Euclidean vs Manhattan vs Chebyshev
1. Side-by-Side View
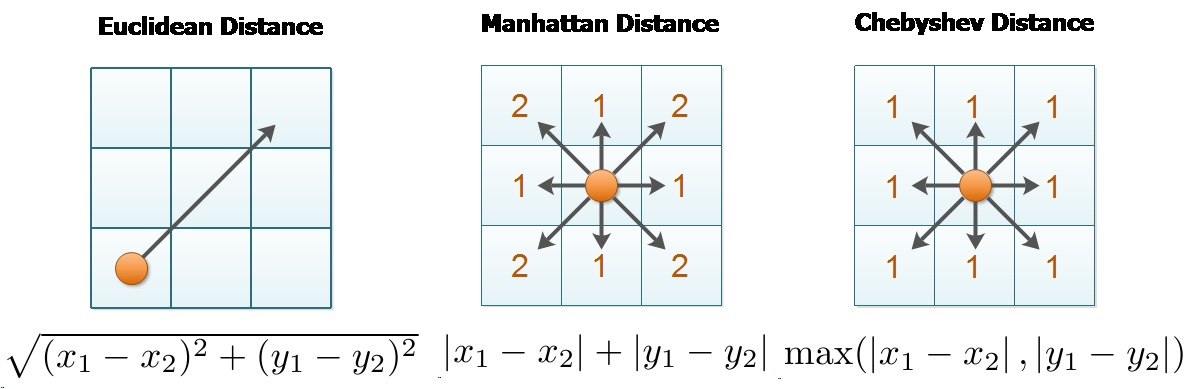
2. Overlay View: Assuming (0,0) as a one of the point
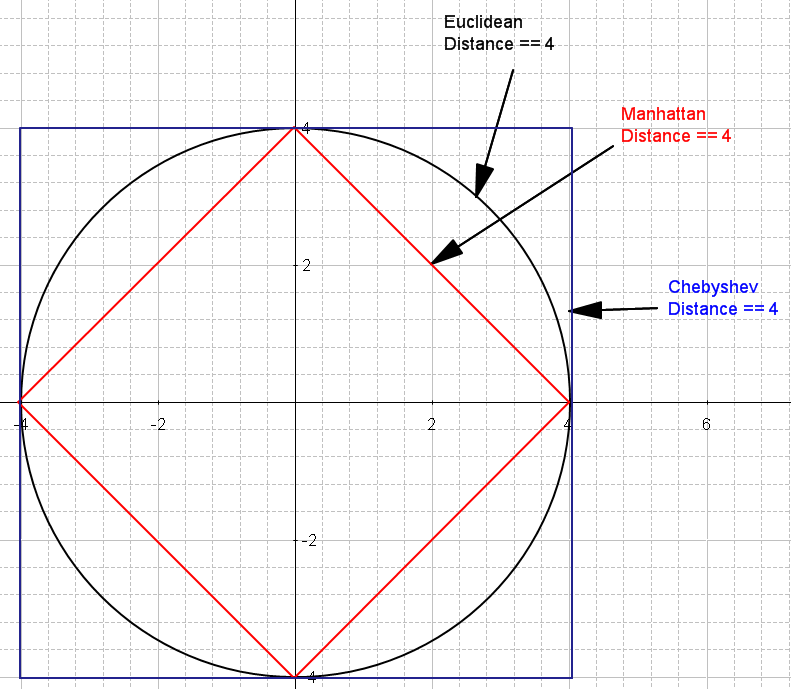
- Euclidean: A circle (all points equidistant)
- Manhattan: A diamond (rotated square)
- Chebyshev: A square aligned with axes
Comparison (for
- Euclidean:
- Manhattan:
- Chebyshev: