K-means Clustering
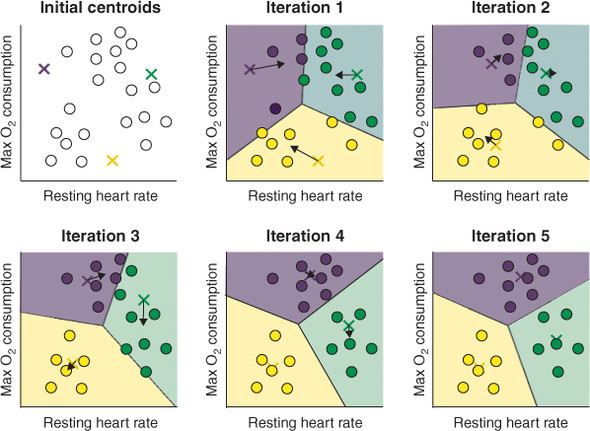
K-Means is a centroid-based, iterative partition algorithm that groups unlabeled data into
Key Concepts
- Unsupervised ML: Learns patterns from unlabeled data.
- Centroid-based: Each cluster is defined by its center (
of points). - Hard Clustering: Each point belongs to exactly one cluster.
- Objective: Minimizes the Within-Cluster Sum of Squares (WCSS).
How it Works (The Algorithm)
- Initialization: Choose
points as initial centroids. - Assignment: For each data point
, find the closest centroid (usually using Euclidean distance). - Centroid Update: For each cluster, calculate the mean of all points assigned to it. This mean becomes the new centroid.
- Convergence: Repeat steps 2 and 3 until centroids no longer move significantly or a maximum number of iterations is reached.
Internal Evaluation Metrics
During the iterative process, the algorithm monitors two key metrics:
-
Within-Cluster Sum of Squares (WCSS) / Inertia:
- Measures Cohesion (how tight the clusters are).
- Goal: Minimize this value.
- During each iterations, WCSS decreases.
-
Between-Cluster Sum of Squares (BCSS):
- Measures Separation (how far apart clusters are).
- Goal: Maximize this value.
- During each iterations, BCSS increases.
Finding the Optimal 'K' (Model Selection)
1. The Elbow Method
The Elbow method is used to find the "sweet spot" for
- Run K-Means for a range of
values (e.g., 1 to 10). - Calculate the SSE (Inertia) for each
. - Plot
vs. SSE. - Inflection Point: Identify the "elbow"—the point where the rate of decrease in SSE slows down significantly.
2. Silhouette Analysis
While the Elbow method is popular, Silhouette Analysis is often more robust as it considers both cohesion and separation.
- Score Range:
- Interpretation: A high average silhouette score indicates well-defined clusters.
Best Practices for Data Scientists
- Always Scale Features: K-Means is extremely sensitive to feature magnitude due to Euclidean distance. Use normalization/standardization is MUST.
- K-Means++ Initialization: Standard random initialization can lead to poor local minima. Use
init='k-means++'. - Multiple Runs: Use the
n_initparameter to run the algorithm with different starting points and pick the one with the lowest inertia. - Post-Processing: Analyze cluster centroids to understand the meaning of each group.
Limitations of K-Means
While K-Means is widely used due to its simplicity and speed, it has several significant limitations:
1. Sensitivity to Initial Centroid Selection:
- The algorithm can converge to local minima depending on where the initial centroids are placed.
- Solution:
- Use K-Means++ for better initialization or
- Run the algorithm multiple times (n_init) and pick the best result.
2. The "K" Problem:
- The user must specify the number of clusters (
) in advance. In real-world data, the optimal is rarely known. - Solution:
- Use the Elbow Method or
- Silhouette Analysis to estimate
.
3. Assumes Spherical Clusters:
- K-Means assumes clusters are convex and isotropic (spherical). It fails to identify clusters with irregular, elongated, or manifold shapes.
- Solution:
- Use density-based clustering like DBSCAN or Spectral Clustering.
4. Sensitive to Outliers:
- Since K-Means minimizes the squared distance (SSE), outliers can pull the centroids away from the true cluster center, distorting the results.
- Solution:
- Use K-Medoids (PAM) or detect and remove outliers beforehand.
5. Sensitive to Feature Scaling:
- Features with larger numerical ranges will dominate the distance calculation (Euclidean distance).
- Solution:
- Always perform Feature Scaling (Standardization/Normalization) before clustering.
6. Hard Assignment (Non-Probabilistic):
- K-Means is a "hard" clustering algorithm; every point belongs to exactly one cluster. It doesn't handle overlapping clusters well.
- Solution:
- Gaussian Mixture Models (GMM) or
- Fuzzy C-Means for soft assignments.
7. Inability to Handle Categorical Data:
- K-Means relies on calculating means, which is not mathematically sound for categorical variables.
- Solution:
- K-Modes for categorical data or
- K-Prototypes for mixed data types.
8. Varying Densities and Sizes:
- K-Means struggles when clusters have significantly different sizes or densities because it effectively "cuts" the space using Voronoi cells.
The Voronoi cells ➛ The boundaries formed by halfway points between centroids and do not account for density. As a result, if a large, low-density cluster is near a small, high-density cluster, the boundary will not correctly separate them. Instead, it often cuts through the dense cluster to pick up points for the larger, sparse one.
9. Curse of Dimensionality:
- In very high-dimensional spaces, Euclidean distance becomes less meaningful (all points appear equally far away).
Time Complexity
The time complexity of K-Means is
: Number of data points : Number of clusters : Number of iterations to converge : Number of dimensions (features)
Generally, K-Means is considered