Advanced Categorical Encoders
I. Binary Encoding
Binary Encoding is a memory-efficient technique that combines the benefits of LabelEncoding and One-Hot Encoding. It converts categories to integers, then represents those integers in binary format, creating ⌈log₂(K)⌉ columns instead of K columns.
Example with Visual Representation
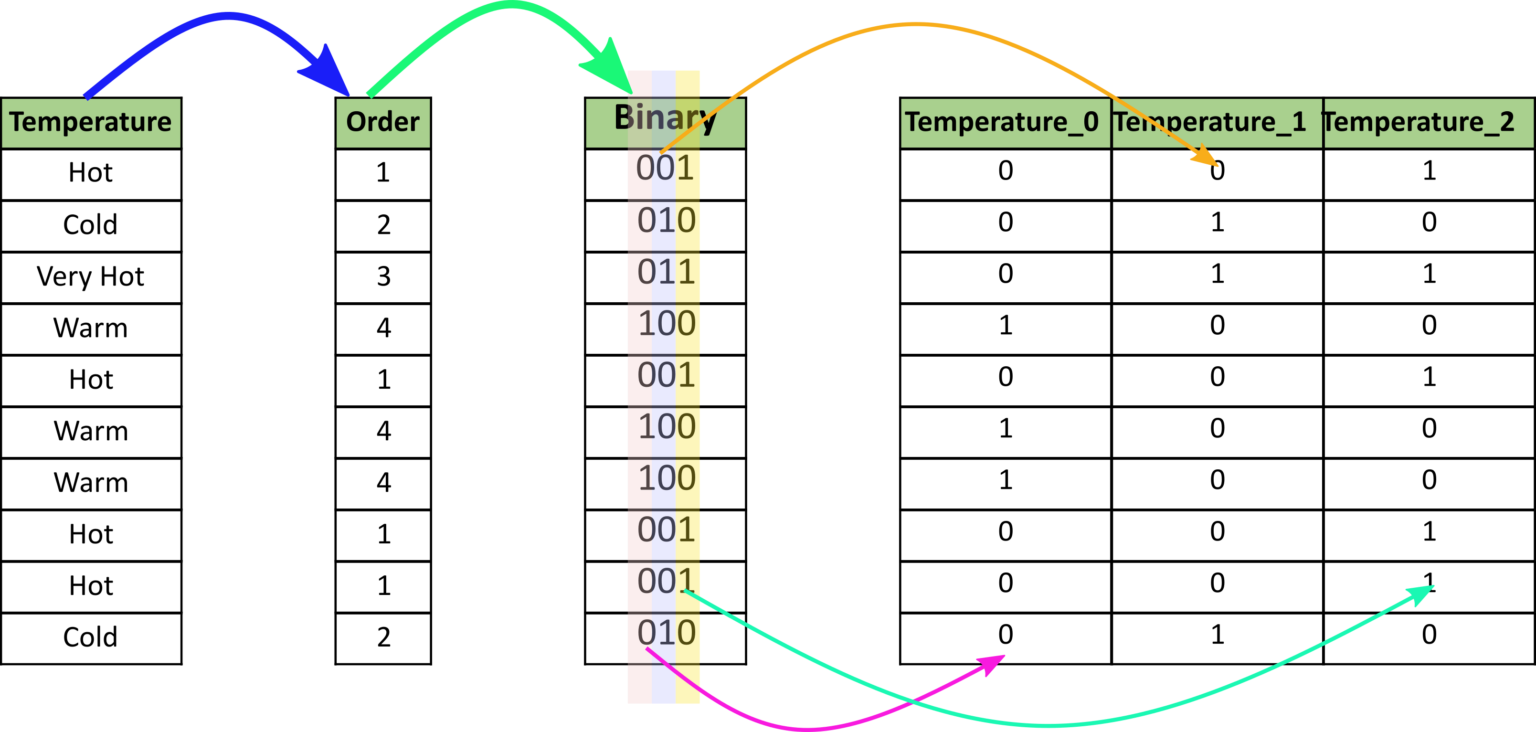
How Binary Encoding Works
- Assign integers to each category (0, 1, 2, ..., K-1)
- Convert to binary representation
- Split binary digits into separate columns
- Result: ⌈log₂(K)⌉ binary columns
Dimensionality reduction:
- 10 categories → 4 columns (vs 10 with One-Hot)
- 100 categories → 7 columns (vs 100 with One-Hot)
- 1000 categories → 10 columns (vs 1000 with One-Hot)
- Formula: Columns needed = log₂(K)
Why Binary Encoding Matters
Dramatic Dimensionality Reduction
Binary Encoding provides exponential compression compared to One-Hot Encoding while preserving more structure than simple Label Encoding.
Space savings examples:
- 50 categories: 6 binary columns vs 50 one-hot columns (88% reduction)
- 500 categories: 9 binary columns vs 500 one-hot columns (98.2% reduction)
- 1000 categories: 10 binary columns vs 1000 one-hot columns (99% reduction)
Preserves Some Categorical Structure
Unlike Label Encoding, the binary representation doesn't impose a single false ordinal relationship. Each binary column represents a different "aspect" of the category that can be learned independently.
Memory and Computation Efficiency
Significantly reduces memory footprint and speeds up training, especially important for:
- Large datasets with high-cardinality features
- Real-time prediction systems
- Resource-constrained environments
When to Use Binary Encoding
Ideal scenarios:
- High-cardinality features (50-10,000+ categories)
- Example: User IDs, product IDs, session IDs, ZIP codes, IP addresses
- Much more efficient than One-Hot Encoding
- Memory-constrained environments
- Limited RAM or storage
- Real-time prediction systems
- Embedded systems or mobile devices
- Tree-based models with high cardinality
- Works well with Random Forests, XGBoost, LightGBM
- Better than simple Label Encoding
- Trees can learn complex patterns from binary features
- When you need balance
- Between One-Hot's dimensionality and Label's arbitrariness
- When Target Encoding isn't appropriate (to avoid leakage)
- Neural networks
- Can learn from binary representations
- Much more efficient than one-hot for high cardinality
When to Avoid Binary Encoding
Not recommended for:
-
Low-cardinality features (<10 categories)
- One-Hot Encoding is simpler and more interpretable
- Binary encoding adds unnecessary complexity
-
When interpretability is critical
- Binary columns are hard to interpret
- Each column represents a "bit" not a category
- Stakeholders may not understand the encoding
-
When categories have natural ordering
- Use Ordinal Encoding instead to preserve the order
-
Very small datasets
- Overhead may not be worth it
- Simple One-Hot might work fine
Advantages and Limitations
Advantages:
- ✅ Exponential dimensionality reduction: log₂(K) vs K columns
- ✅ Works with all algorithm types
- ✅ More structured than Label Encoding
- ✅ Memory efficient for high cardinality
- ✅ Fast training and prediction
- ✅ Handles unseen categories (can assign new binary codes)
- ✅ No sparsity issues like One-Hot Encoding
Limitations:
- ⚠️ Less interpretable than One-Hot or Label Encoding
- ⚠️ Arbitrary ordering still matters (affects binary representation)
- ⚠️ Bit patterns have no semantic meaning
- ⚠️ May not capture category relationships well
- ⚠️ Overkill for low cardinality
- ⚠️ Requires more columns than simple Label Encoding
Python Implementation
II. Feature Hashing (Hash Encoding)
Feature Hashing, uses a hash function to map categorical values to a fixed number of bins. Unlike other encodings, it doesn't require knowing all categories in advance, making it perfect for streaming data and very high cardinality features.
Example: Hash function maps categories to 4 bins:
| Category | hash(Category) % 4 | Bin_0 | Bin_1 | Bin_2 | Bin_3 |
|---|---|---|---|---|---|
| Red | 2 | 0 | 0 | 1 | 0 |
| Blue | 0 | 1 | 0 | 0 | 0 |
| Green | 3 | 0 | 0 | 0 | 1 |
| Yellow | 2 | 0 | 0 | 1 | 0 |
Notice: Red and Yellow hash to the same bin (collision).
How Feature Hashing Works
- Choose number of bins (n_features, typically power of 2)
- Apply hash function to each category
- Map to bin: bin_index = hash(category) % n_features
- Set value in that bin (usually 1, or signed based on second hash)
- Result: Fixed-size representation regardless of cardinality
Key properties:
- Fixed dimensionality: Always produces exactly n_features columns
- No training required: No need to fit on training data
- Handles unseen categories: New categories automatically hashed
- Deterministic: Same category always hashes to same bin
Why Feature Hashing Matters
Handles Unbounded Cardinality
Perfect for features where you don't know all possible values in advance:
- Streaming data with new categories appearing constantly
- Text data with evolving vocabulary
- User-generated content (hashtags, usernames, URLs)
No Memory of Categories
Doesn't store a mapping dictionary, making it extremely memory-efficient even with millions of categories.
Online Learning Compatible
Works seamlessly in online/streaming settings where you can't make two passes over the data.
Constant Space Complexity
Memory usage is O(n_features), independent of actual number of categories.
When to Use Feature Hashing
Ideal scenarios:
- Very high cardinality (10,000+ categories)
- Examples:
- URLs, email addresses, full text tokens,
- User IDs in systems with millions of users
- Product catalogs with hundreds of thousands of SKUs
- Examples:
- Streaming/online learning
- Real-time systems that can't wait for retraining
- Data where new categories appear constantly
- Systems that need to handle unseen categories gracefully
- Memory-constrained production
- Can't store large category mappings
- Need fixed-size models
- Embedded or edge devices
- Text and NLP applications
- Bag-of-words with large vocabularies
- N-grams and character-level features
- Feature crosses and interaction terms
- When you can't afford two passes
- Single-pass data processing
- Cannot collect all categories first
When to Avoid Feature Hashing
Not recommended for:
-
Low-to-medium cardinality (<100 categories)
- One-Hot or Binary Encoding are better
- Collisions waste representational capacity
-
When interpretability is critical
- Hash collisions make debugging difficult
- Can't trace predictions back to original categories
- Stakeholders need to understand feature importance
-
Small datasets
- Collisions have larger impact
- Better encodings available
-
When you need perfect accuracy
- Collisions introduce information loss
- For critical applications, consider alternatives
Advantages and Limitations
Advantages:
- ✅ Fixed dimensionality: Choose exact number of features
- ✅ No training required: Works immediately on any data
- ✅ Handles unseen categories: Automatically
- ✅ Memory efficient: No category dictionary stored
- ✅ Fast: O(1) encoding time per category
- ✅ Online learning compatible
- ✅ Scales to millions of categories
- ✅ Great for text data and sparse features
Limitations:
- ⚠️ Hash collisions: Different categories map to same bin
- ⚠️ Information loss: Collisions are irreversible
- ⚠️ Harder to interpret: Can't map bins back to categories
- ⚠️ Tuning required: Need to choose n_features wisely
- ⚠️ May need more features: To reduce collision rate
- ⚠️ Debugging is difficult: Which categories collided?
Understanding Hash Collisions
Collision rate depends on:
- Number of categories (K)
- Number of hash bins (n_features)
- Hash function quality
Birthday paradox applies: collisions happen sooner than expected!
Rule of thumb: Use n_features ≈ 2K to keep collision rate low
Example collision rates:
- 100 categories, 50 bins → ~60% collision probability
- 100 categories, 200 bins → ~30% collision probability
- 1000 categories, 2000 bins → ~30% collision probability
Python Implementation
III. Summary
When to Use Each Encoder
Binary Encoding:
- ✅ High cardinality (50-10,000 categories)
- ✅ Need dimensionality reduction
- ✅ Tree-based models
- ✅ Balance between efficiency and information preservation
Feature Hashing:
- ✅ Very high cardinality (1000+ categories)
- ✅ Streaming/online learning
- ✅ Text data and NLP
- ✅ Unknown categories in production
- ✅ Memory-constrained environments
Common Pitfalls to Avoid
- Binary encoding for low cardinality — overkill and less interpretable
- Too few hash bins — excessive collisions destroy information
- Not monitoring collision rates — can silently degrade performance
- Forgetting to handle unseen categories — production failures
- Ignoring computational cost — some encodings are slower
- Over-engineering — simple One-Hot often works fine
There's no one-size-fits-all encoding. The best choice depends on:
- Your data characteristics (cardinality, distribution)
- Your algorithm (linear vs tree-based vs neural network)
- Your constraints (memory, interpretability, production requirements)
- Your objectives (accuracy vs speed vs explainability)