Blended Stacking
Blended Stacking is a variant of stacking ensemble methods that uses a holdout validation approach to train the meta-model. Unlike traditional stacking with cross-validation, blending relies on a strict holdout dataset (the "blend validation set") to generate predictions for training the meta-learner. This approach prevents data leakage and provides a computationally efficient way to combine multiple base models.
Overview
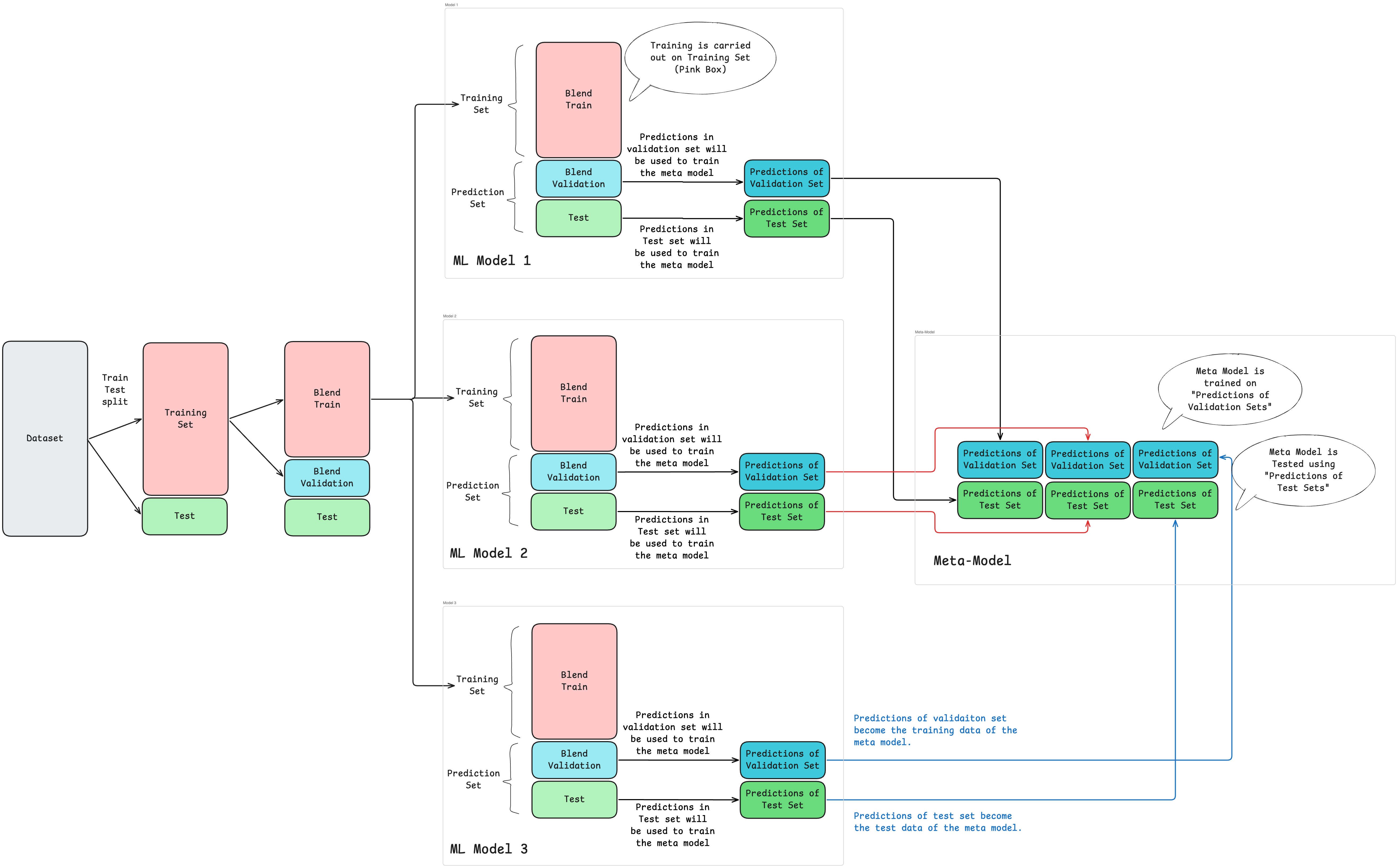
In blended stacking, the training data is split into three distinct sets:
- Blend Train Set: Used to train base models
- Blend Validation Set: Used to generate predictions for training the meta-model
- Test Set: Used for final evaluation (never seen during training)
The key distinction from traditional stacking is that blending uses a simple train-validation split rather than cross-validation, making it faster but potentially less data-efficient.
Implementation Process
Level 0: Base Model Development
Step 1: Data Partitioning
First, split the main dataset into a training set (typically 80%) and a test set (remaining 20%). The test set is reserved exclusively for final evaluation.
Next, partition the training set into two subsets:
- Blend Train (e.g., 70% of training data): For training base models
- Blend Validation (e.g., 30% of training data): For generating meta-model training data
Step 2: Train Base Models
Train all base models (Level 0 learners) using only the Blend Train dataset. Common choices include:
- Random Forest
- Gradient Boosting Machines (XGBoost, LightGBM, CatBoost)
- Support Vector Machines
- Neural Networks
- Any diverse set of algorithms
Step 3: Generate Validation Predictions
Pass the Blend Validation dataset through each trained base model to generate out-of-sample predictions. These predictions form the foundation for meta-model training.
Level 1: Meta-Model Training
Step 4: Construct Meta-Training Dataset
Compile the predictions from Step 3 into a new dataset where:
- Each column represents predictions from one base model
- Each row corresponds to one sample from the Blend Validation set
- For example, with 3 base models, you'll have a 3-column dataset
Note: In pure blending, the original features are typically not included; only base model predictions serve as meta-features. However, some implementations may optionally include original features alongside predictions.
Step 5: Train the Meta-Model
Fit the meta-model (Level 1 learner) using:
- Input features: Base model predictions from Step 4
- Target values: Actual labels from the Blend Validation set
The meta-model learns the optimal way to combine base model predictions. Common meta-models include:
- Logistic Regression (for classification)
- Linear Regression (for regression tasks)
- Ridge or Lasso Regression (for regularization)
- Even simple averaging or weighted averaging
Final Phase: Inference and Evaluation
Step 6: Generate Test Set Predictions
Pass the test set through all trained base models to obtain their predictions. This produces the same structure as in Step 3, but for test data.
Step 7: Generate Final Predictions
Feed the base model predictions from Step 6 into the trained meta-model. The meta-model applies the combination strategy learned during training to produce the final ensemble predictions.
Important: The meta-model does not undergo any training at this stage; it simply applies the learned weights and combination logic.
Step 8: Evaluate Performance
Compare the final ensemble predictions against the actual test set labels to calculate performance metrics (accuracy, F1-score, RMSE, etc.).
Diagrammatic Workflow
Key Differences: Blending vs. Traditional Stacking
| Aspect | Blending | Traditional Stacking |
|---|---|---|
| Validation Strategy | Single holdout split | K-fold cross-validation |
| Data Usage | Less efficient (holdout unused by base models) | More efficient (all data used through CV) |
| Computation Time | Faster (single split) | Slower (K training rounds) |
| Risk of Overfitting | Lower (strict separation) | Slightly higher if not careful |
| Meta-Model Training Data | Smaller (only holdout set) | Larger (out-of-fold predictions) |
Advantages
- Computational Efficiency: Significantly faster than cross-validation-based stacking, making it suitable for large datasets or time-constrained projects
- Simplicity: Easier to implement and understand, with straightforward train-validation split logic
- Reduced Overfitting Risk: The strict separation between training and validation sets provides robust out-of-sample predictions
- Scalability: Works well when you have sufficient data and need quick results
Limitations
- Data Inefficiency: The holdout approach means the base models never learn from the blend validation data, which can be wasteful, especially with small datasets
- Potential Underfitting: With limited training data, base models may not reach their full potential
- Variance in Performance: Results can be sensitive to the random split, particularly with smaller datasets
- Suboptimal for Small Datasets: Not recommended when data is scarce, as the multiple splits significantly reduce effective training size
When to Use Blended Stacking
Best suited for:
- Large datasets where data efficiency is less critical
- Time-sensitive projects requiring quick ensemble results
- Scenarios where computational resources are limited
- Kaggle competitions with large training sets and tight deadlines
Avoid when:
- Working with small or medium-sized datasets
- Maximum predictive performance is critical and computation time is not a constraint
- You need to leverage every bit of available training data
Practical Tips
- Split Ratios: Common splits are 80-20 or 70-30 for train-test, and 70-30 for blend train-validation
- Model Diversity: Use diverse base models to capture different patterns in the data
- Meta-Model Selection: Start simple (linear models) before trying complex meta-learners
- Stratification: For classification tasks, use stratified splits to maintain class distribution
- Feature Engineering: Strong feature engineering at the base model level can significantly improve ensemble performance
Related Concepts
- Stacking Ensemble: The general stacking framework
- Cross-Validation Stacking: Alternative approach using K-fold CV
- Ensemble Methods: Broader category of combining multiple models
Pros:
- Very fast; low computational cost
- Simple to implement and understand
- Reduced overfitting risk through strict data separation
Limitations:
- Inefficient use of training data (blend validation set only used for meta-model training)
- Highly wasteful of data, which is risky if your dataset isn't large
- Performance can vary based on the random split
- Not recommended for small to medium-sized datasets