Complete Forward & Backward Propagation Example
Overview: The Big Picture
| Phase | Purpose | Key Output |
|---|---|---|
| Forward Propagation | Pass input through the network to get a prediction | Prediction |
| Backward Propagation | Compute gradients — how much each weight contributed to the error | Gradients |
| Weight Update | Adjust weights to reduce the error | New weights |
One complete cycle (Forward → Backward → Update) = One Training Iteration
Repeat for many iterations (epochs) until the loss is minimized and predictions are accurate.
Network Architecture
Input Layer (2 neurons) → Hidden Layer (2 neurons) → Output Layer (1 neuron)
- Activation Function (Hidden): Sigmoid:
- Activation Function (Output): Sigmoid
- Loss Function: Binary Cross-Entropy (BCE):
Notation Reference
| Symbol | Meaning |
|---|---|
| Input feature |
|
| Weight from input |
|
| Weight from hidden neuron |
|
| Bias for neuron |
|
| Pre-activation (weighted sum) at layer |
|
| Activation (output after sigmoid) at layer |
|
| Network's prediction (output layer activation) | |
| True target label | |
| Loss (error) | |
| Error signal at layer |
|
| Learning rate |
Sample Data (5 rows, 2 columns)
| Sample | |||
|---|---|---|---|
| 1 | 0.1 | 0.2 | 0 |
| 2 | 0.4 | 0.5 | 1 |
| 3 | 0.3 | 0.6 | 1 |
| 4 | 0.7 | 0.1 | 0 |
| 5 | 0.9 | 0.8 | 1 |
Initialized Weights and Biases
Input → Hidden Layer:
Hidden → Output Layer:
Diagrammatic Representation
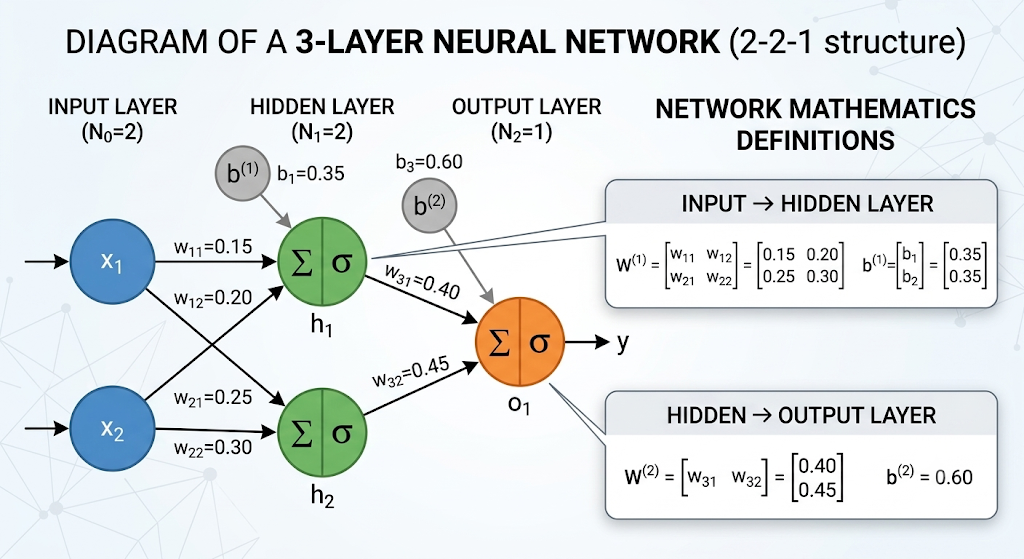
👉 Both Forward and Backward Propagation is detailed for Sample 1:
, ,
Forward Propagation
5-Step Forward Propagation Steps
Step 1: Input to Hidden Layer
Compute weighted sum (
Step 2: Apply sigmoid activation:
Step 3: Hidden to Output Layer
Compute weighted sum for output:
Step 4: Apply sigmoid activation (final prediction)
Step 5: Calculate Loss (Binary Cross-Entropy)
Forward Propagation Results for All 5 Samples
| Sample | BCE Loss | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.1 | 0.2 | 0.415 | 0.430 | 0.6023 | 0.6058 | 1.1135 | 0.7528 | 0 | 1.3976 |
| 2 | 0.4 | 0.5 | 0.535 | 0.580 | 0.6307 | 0.6411 | 1.1407 | 0.7757 | 1 | 0.2538 |
| 3 | 0.3 | 0.6 | 0.545 | 0.590 | 0.6330 | 0.6434 | 1.1428 | 0.7760 | 1 | 0.2534 |
| 4 | 0.7 | 0.1 | 0.480 | 0.520 | 0.6177 | 0.6272 | 1.1293 | 0.7737 | 0 | 1.4858 |
| 5 | 0.9 | 0.8 | 0.685 | 0.770 | 0.6649 | 0.6836 | 1.1734 | 0.8282 | 1 | 0.1884 |
Total BCE Loss:
Backward Propagation
We compute gradients using the chain rule and propagate errors backward.
Visual Representation of Backpropagation
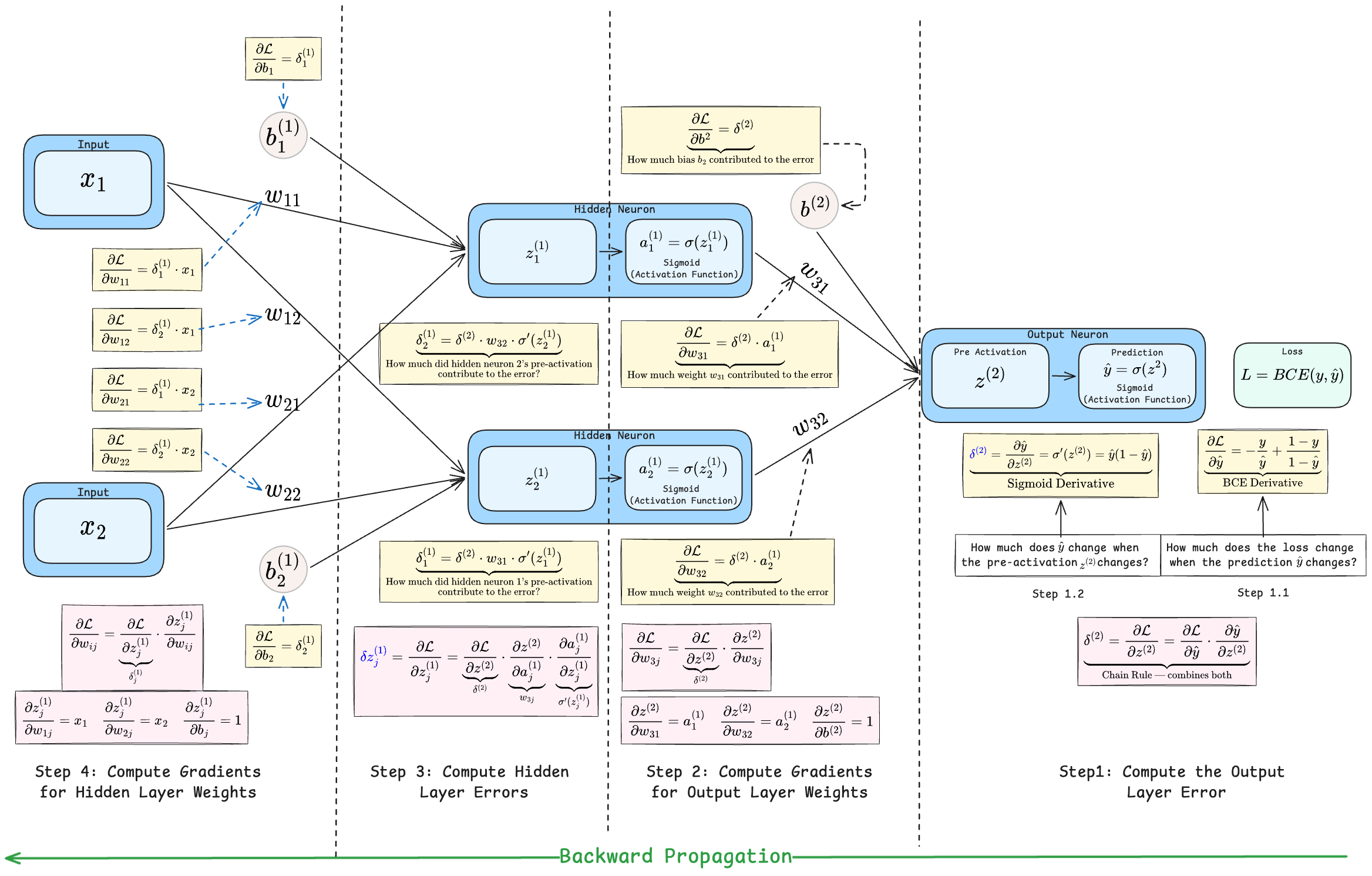
5-Step Backward Propagation Steps
Step 1: Compute the Output Layer Error
- This error signal tells us the "blame" assigned to the output neuron (
), which we'll use to update its weights and propagate backward. - How — Calculate the error at the output neuron by finding
the difference between the actual target and the prediction, scaled by the derivative of its activation function.
Step 1.1 — Binary Cross-Entropy Derivative:
👉 Question — How much does the loss change when the prediction
➢ This measures the sensitivity of our loss function to prediction errors. If the prediction is far from the truth, this value is large.
Step 1.2 — Sigmoid Derivative:
Question — How much does
➢ This captures magnitude — how "steep" the sigmoid curve is at the current output. The slope is largest near
Step 1.3 — The Output Neuron Error (
Question — How the loss changes with the pre-activation
➢ It acts as the primary scaling factor, dictating the overall direction and magnitude of the necessary correction at the end of the network.
Calculation: The Multiplication (Chain Rule)
We can see the calculations in 2 ways
Method 1: Substitution:
When you substitute (i) and (ii) and simplify, a remarkably clean result emerges:
Method 2: Equation Simplification
This isn't a coincidence — BCE was designed specifically to pair with sigmoid. The "ugly" fractions in the BCE derivative perfectly cancel with the sigmoid derivative, giving us the clean
Step 2: Gradients for Output Layer Weights
- Find
, , ➛ How much does each output-layer weights, the bias, or the activations from the previous layer contribute to the loss? - These gradients tell us how much a specific weight connecting the hidden layer to the output layer needs to adjust and by how much to reduce the error.
Recall that
- The hidden activation
and is the input flowing into weight and respectively. - A larger input means that weight had more influence on the output — so it deserves more "blame" for the error.
The Chain Rule for Each Parameter
Each gradient is found by extending the chain rule one more step — from z⁽²⁾ back to the weight:
Local derivatives are simply:
The Three Gradients
Gradient for weight
Question—How much weight
Gradient for weight
Question—How much weight
Gradient for bias
Question—How much Bias
Bias has no input multiplier, just the error
Key insight — Gradient = Error × Input
- A weight's gradient depends on two things:
- The output error (
) — how wrong the network was. - The incoming activation (
) — how active that connection was. - If a hidden neuron's activation (aⱼ⁽¹⁾) is large, its weight gets a bigger adjustment, because it was more "responsible" for the output.
- If the activation is near zero, that weight barely changes — it had little influence.
- The output error (
Step 3: Hidden Layer Errors
- Find
and ➛ How much does each hidden neuron's pre-activation contribute to the loss? - These error signals tell us how much "blame" each hidden neuron deserves, which we'll use to update the input-to-hidden weights.
Recall that
- The weight
determines how much hidden neuron influences the output. - A larger weight means that hidden neuron had more influence on the output — so it deserves more "blame" for the error.
The Chain Rule for Each Parameter
Each hidden error is found by extending the chain rule two more steps — from
Since
This simplifies to the general formula:
The Two Hidden Error Signals
| Term | What it represents | Value |
|---|---|---|
| Output error (already computed in Step 1) | ||
| Connection strength from hidden neuron 1 to output | ||
| Connection strength from hidden neuron 2 to output | ||
| Sigmoid derivative — how "responsive" neuron 1 was | ||
| Sigmoid derivative — how "responsive" neuron 2 was |
Error for hidden neuron 1 (
Question — How much did hidden neuron 1's pre-activation contribute to the error?
Error for hidden neuron 2 (
Question — How much did hidden neuron 2's pre-activation contribute to the error?
Key Insight — Hidden Error = Output Error × Weight × Local Slope
- A hidden neuron's error depends on three things:
- The output error (
) — how wrong the network was overall. - The connection weight (
) — how strongly this neuron influenced the output. - The activation slope (
) — how responsive this neuron was at its current input.
- The output error (
- If a neuron was strongly connected and highly responsive, it receives more blame and will be adjusted more.
- If the sigmoid is saturated (output near 0 or 1),
, so very little error flows backward — this is the vanishing gradient problem.
Step 4: Gradients for Hidden Layer Weights
- Find
, , , , , ➛ How much does each input-to-hidden weight and bias contribute to the loss? - These gradients tell us how to adjust the connections between the input layer and the hidden layer to reduce the error.
Recall that
- The input
is the value flowing into weight . - A larger input means that weight had more influence on the hidden neuron's output — so it deserves more "blame" for the error.
The Chain Rule for Each Parameter
Since we already computed
Since
The Six Gradients
| Term | What it represents | Value |
|---|---|---|
| Hidden neuron 1 error (from Step 3) | ||
| Hidden neuron 2 error (from Step 3) | ||
| Input feature 1 | ||
| Input feature 2 |
Gradient for weight
Question — How much did weight
Gradient for weight
Question — How much did weight
Gradient for weight
Question — How much did weight
Gradient for weight
Question — How much did weight
Gradient for bias
Question — How much did bias
Bias has no input multiplier, just the error
Gradient for bias
Question — How much did bias
Bias has no input multiplier, just the error
Key Insight — Gradient = Error × Input (Same Pattern as Step 2!)
- A weight's gradient depends on two things:
- The hidden neuron's error (
) — how much blame this neuron received. - The incoming input (
) — how active that input was.
- The hidden neuron's error (
- If an input is large, the weights connected to it get bigger adjustments, because they had more influence.
- This pattern — Gradient = Error × Input — repeats at every layer in deep networks, making backpropagation elegant and scalable.
Step 5: Weight Updates
Calculate new values of
Using gradient descent:
Assumption
➢ Learning Rate
| Weight | Old Value | Gradient | New Value |
|---|---|---|---|
| 0.15 | 0.00721 | 0.1464 | |
| 0.25 | 0.01442 | 0.2428 | |
| 0.20 | 0.00809 | 0.1960 | |
| 0.30 | 0.01618 | 0.2919 | |
| 0.35 | 0.0721 | 0.3139 | |
| 0.35 | 0.0809 | 0.3096 | |
| 0.40 | 0.4533 | 0.1733 | |
| 0.45 | 0.4561 | 0.2219 | |
| 0.60 | 0.7528 | 0.2236 |
What Happens Next?
-
Repeat for all samples — In practice, you'd compute gradients for all 5 samples and average them (batch gradient descent), or update after each sample (stochastic gradient descent).
-
Multiple Epochs — One pass through all samples = 1 epoch. Training typically requires hundreds or thousands of epochs until loss converges.
-
Monitor Loss — After each epoch, check if
is decreasing. If it plateaus or increases, adjust learning rate or check for issues. -
Evaluate — Once trained, test on unseen data to measure generalization.
Key Insight: The beauty of backpropagation is that the same pattern — Gradient = Error × Input — repeats at every layer, making it computationally efficient and scalable to deep networks.