One-Hot Encoding (OHE)
One-Hot Encoding is a fundamental technique for converting categorical variables into a numerical format that machine learning algorithms can process. It transforms a categorical feature with
How One-Hot Encoding Works
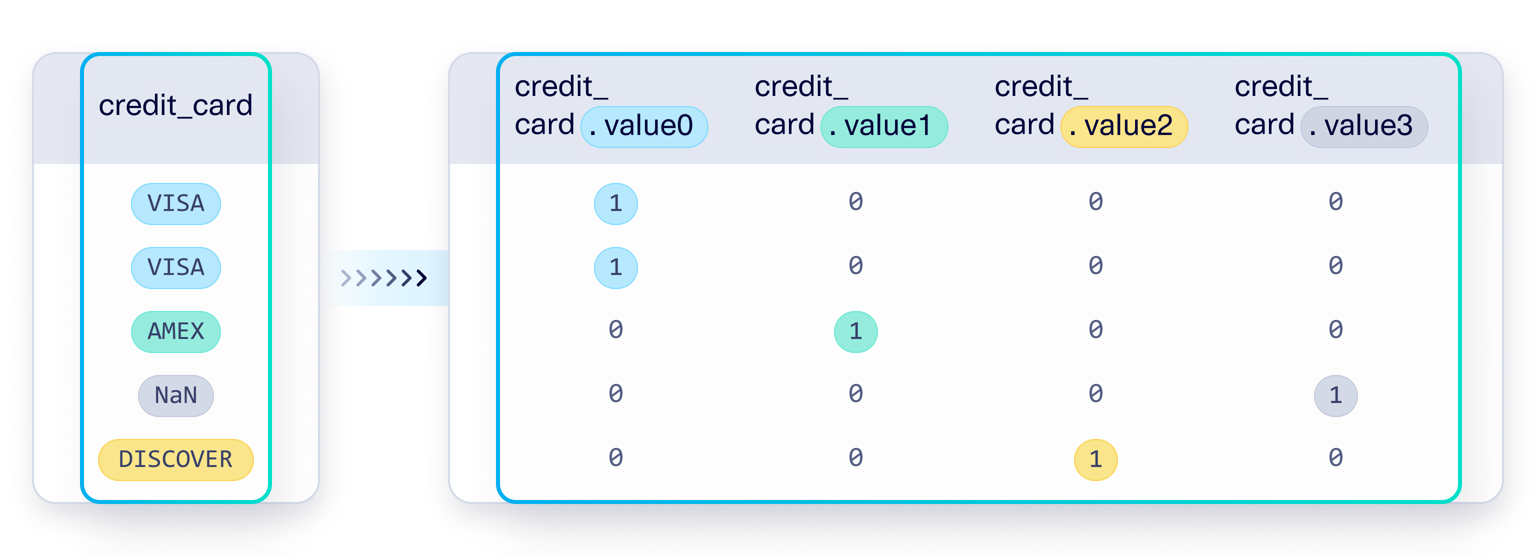
Example: Consider a simple dataset with a categorical variable "City":
| City | City_NYC | City_LA | City_SF | |
|---|---|---|---|---|
| NYC | → | 1 | 0 | 0 |
| LA | → | 0 | 1 | 0 |
| SF | → | 0 | 0 | 1 |
| NYC | → | 1 | 0 | 0 |
Each unique category becomes its own binary column, creating a sparse representation where exactly one column contains a 1 for each row.
Why One-Hot Encoding Matters
Preserving Categorical Nature
Many categorical variables have no inherent order (e.g., "Male" and "Female", or "Red", "Green", "Blue"). If we assigned arbitrary numerical values (e.g., Red=0, Green=1, Blue=2), the model would incorrectly interpret these as having a meaningful order or magnitude. One-Hot Encoding eliminates this issue by treating each category as an independent feature.
Algorithm Compatibility
Most machine learning algorithms—particularly linear models, logistic regression, and neural networks—require numerical input. One-Hot Encoding ensures categorical variables are properly formatted without introducing false relationships.
Improved Interpretability
In linear models, each one-hot encoded feature receives its own coefficient, making it easy to interpret the impact of each category relative to a baseline (reference category).
When to Use One-Hot Encoding
Ideal scenarios:
- Nominal categorical variables with no natural ordering: city names, product categories, color, department, browser type
- Low-to-moderate cardinality features (typically fewer than 10-15 unique categories)
- Linear models: Linear regression, logistic regression, linear SVM, neural networks
- Distance-based algorithms: k-NN, K-means clustering (where you want equal weight per category)
When to Avoid or Use Caution
Not recommended for:
-
High-cardinality features (hundreds or thousands of unique values): user IDs, ZIP codes, URLs, product SKUs
- Creates massive dimensionality (curse of dimensionality)
- Leads to sparse matrices and memory issues
- Increases risk of overfitting
-
Tree-based models: Decision trees, Random Forests, XGBoost, LightGBM
- These models can handle categorical variables natively or work well with simpler encodings
- OHE may actually hurt performance by fragmenting the data
-
Ordinal categories: When categories have a meaningful order (e.g., "Low", "Medium", "High"), use ordinal encoding instead
-
Streaming data with new categories: If you expect frequent new categories at inference time, consider alternatives like hashing or learned embeddings
Advantages and Limitations
Advantages:
- Simple, intuitive, and widely supported across ML libraries
- Eliminates artificial ordering between categories
- Works exceptionally well with linear models
- Produces interpretable model coefficients
- Maintains all information from the original categorical variable
Limitations:
- Dimensionality explosion:
categories → features (can be prohibitive for high cardinality) - Increases memory usage and computational cost (though sparse matrices help)
- Multicollinearity risk: Including all dummy variables plus an intercept creates perfect multicollinearity
- Rare categories can lead to overfitting with insufficient training examples
- Cannot handle unseen categories without explicit configuration
Critical Considerations
1. The Dummy Variable Trap
When using models with an intercept term (most regression models), you must drop one category to avoid perfect multicollinearity. This is because if you know the values of
Solution: Use
2. Train/Test Consistency
Always fit the encoder on training data only, then apply the same transformation to test data. Never fit on test data—this causes data leakage.
Solution: Use scikit-learn's Pipeline to ensure consistent transformations.
3. Handling Unseen Categories
What happens when test data contains categories not seen during training?
Options:
handle_unknown='error': Raises an error (default in older sklearn versions)handle_unknown='ignore': Creates a row of all zeros (recommended for production)
4. Memory Considerations
For high-cardinality features, dense matrices can consume excessive memory.
Solution: Use sparse matrix output (sparse=True in sklearn).
5. Alternative Encoding Methods for High Cardinality
- Frequency/Count encoding: Replace categories with their occurrence frequency
- Target encoding: Replace with the mean of the target variable (with cross-validation to prevent leakage)
- Hashing: Use feature hashing to reduce dimensionality
- Grouping: Combine rare categories into an "Other" category
- Embeddings: Learn dense representations (especially useful in deep learning)
Best Practices Summary
- Always use pipelines to prevent data leakage and ensure consistency
- Drop one level when using models with intercepts (use drop='first')
- Set handle_unknown='ignore' for production systems to gracefully handle new categories
- Use sparse matrices for high-cardinality features to save memory
- Consider alternatives (target encoding, hashing, grouping) when dealing with very high cardinality
- For tree-based models, test whether OHE actually improves performance—often ordinal encoding works better
- Monitor dimensionality: If OHE creates hundreds of features, your model may suffer from the curse of dimensionality
- Group rare categories (appearing in <1% of samples) into an "Other" category before encoding
Python Implementation
Dummy encoding
In machine learning, Dummy Encoding and One-Hot Encoding are two very similar techniques for converting categorical data into a numerical format. People often use the terms interchangeably, but there is a key technical difference.
- What it does: It creates
k-1binary columns forkcategories. It drops one category, which becomes the baseline or reference category. - Rule: If you have
kcategories, you getk-1new columns. - Purpose: The main reason for doing this is to avoid multicollinearity (also known as the "dummy variable trap"). This is important for linear models (like Logistic Regression), where perfectly correlated features can cause problems with interpreting model coefficients.
Common Errors & Cautions
- Dropping the "Wrong" Reference: In Dummy Encoding, the dropped category becomes your baseline. If you are studying a drug trial, you should drop the "Placebo" group so all other coefficients tell you how much better the drugs are than the placebo.