Bagging (Bootstrap Aggregating)
Bagging is short for Bootstrap Aggregating, is a parallel ensemble learning technique that mainly aims to reduces variance and prevents overfitting by training multiple models independently on different bootstrap samples of the training data and then aggregating their predictions.
By training models on different bootstrap samples (random samples with replacement), each model sees a slightly different view of the data, capturing different patterns and making different errors. When we aggregate their predictions, individual mistakes tend to cancel out, while correct predictions reinforce each other.
Key Distinctions
Homogeneous Algorithms
- Bagging is typically a homogeneous ensemble method, meaning all individual base learners use the same training algorithm (e.g., all are Decision Trees).
Different Model Versions
- Although the algorithm is the same, each model within the ensemble is a different version. This happens because bagging uses Bootstrap Resampling—creating multiple unique subsets of data by sampling with replacement.
Independent Training
- Each model is trained independently and in parallel, meaning the performance or errors of one model do not influence the training of the next.
Equal Weighting
- Unlike other methods like boosting, every model in a bagging ensemble is given equal weight.
Aggregation Strategy:
- For Classification: Majority voting (each model gets one vote)
- For Regression: Simple averaging of predictions
- Advanced: Weighted voting based on model performance
The Bagging Process
Phase 1: Data Preparation
Step 1: Train-Test Split
Split the main dataset into a training set (typically 80%) and a test set (remaining 20%). The test set is reserved exclusively for final evaluation and is never used during the training or validation process.
Phase 2: Bootstrap Sampling and Model Training
Step 2: Create Bootstrap Samples
For each model in the ensemble (e.g., Model 1 through Model
Key Property: Each bootstrap sample has approximately:
- 63.2% unique samples from the original training data
- 36.8% of original samples not included (these become Out-of-Bag or OOB samples for that specific model)
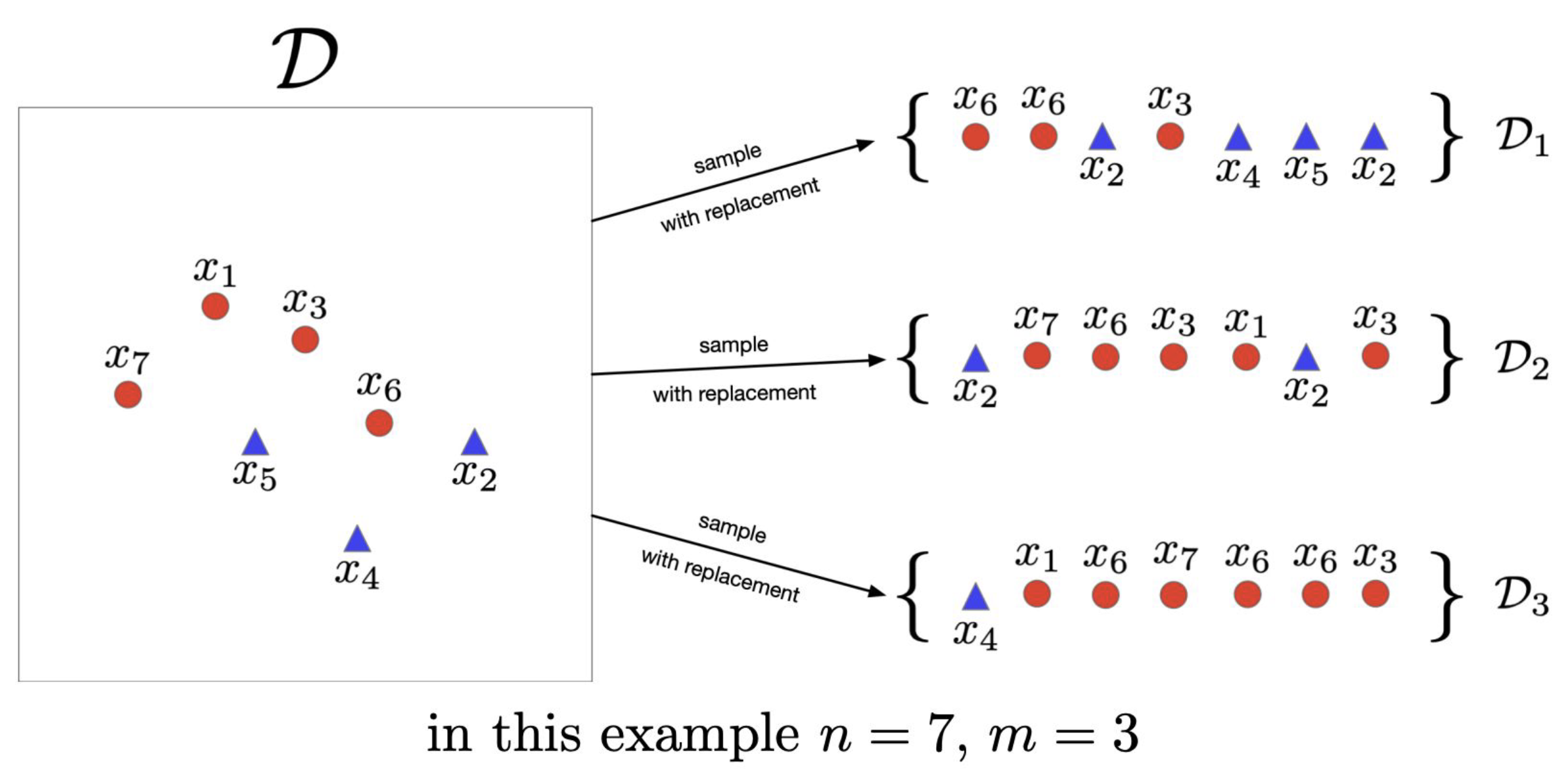
Step 3: Train Individual Models
Train one model on each bootstrap sample independently and in parallel:
Important Characteristics:
- All models use the same algorithm (e.g., all decision trees, all neural networks)
- Models train completely independently with no communication between them
- Training can be parallelized across multiple CPU cores for efficiency
- Each model sees a slightly different view of the data and may overfit to its particular bootstrap sample
Repeat Steps 2-3 for all
Phase 3: Out-of-Bag (OOB) Validation (Optional but Recommended)
After all models are trained, we can perform internal validation using OOB samples without needing a separate validation set.
Step 4: Generate OOB Predictions for Each Sample
For each training sample
- Identify which models did not include this sample in their bootstrap training set (approximately 37% of all models)
- Use only these models to make predictions for
- This gives you an out-of-sample prediction for
without needing a separate validation set.
Step 5: Calculate OOB Error
Aggregate the OOB predictions across all training samples and compare with true labels to compute the OOB Error.
- Classification: Use majority voting from OOB models for each sample
- Regression: Average predictions from OOB models for each sample
- Compare aggregated OOB predictions with true labels to calculate error
Why OOB is valuable: This provides a validation estimate similar to cross-validation but without the computational cost of retraining models. It tells you how well your ensemble generalizes before ever touching the test set.
Phase 4: Final Evaluation on Test Set
Step 6: Generate Test Set Predictions
Once all models are trained, each model makes predictions on the entire test set (data never seen during training).
Step 7: Aggregate Predictions
Combine predictions from all
- Classification:
- Hard Voting: Majority vote (each model gets one vote)
- Soft Voting: Average predicted probabilities across all models
- Regression: Average the predicted values from all models
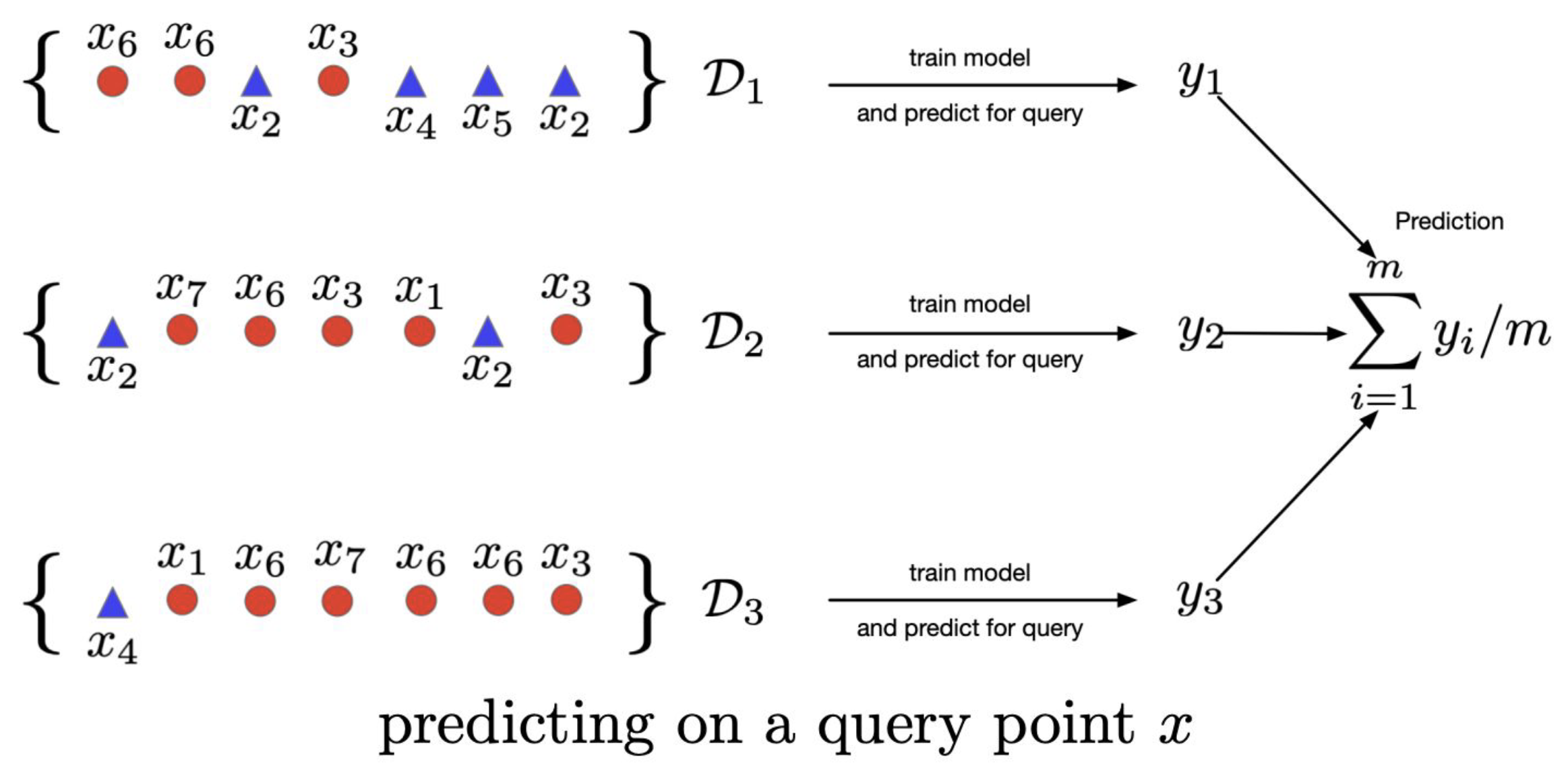
Step 8: Compute Final Performance Metrics
Compare the ensemble's final predictions against the true labels of the test set to calculate performance metrics (accuracy, F1-score, RMSE, etc.).
Mathematical Intuition: Why Bagging Reduces Variance
Consider
This shows that averaging reduces variance by a factor of
Advantages of Bagging
Variance Reduction
- The primary benefit—dramatically reduces overfitting of high-variance models. A deep decision tree that overfits alone becomes robust when bagged with 100+ similar trees.
Parallelization
- Models train independently, making bagging naturally parallelizable. With modern multi-core processors, you can train 100 models almost as fast as 1.
Noise Reduction
- Less sensitive to noisy data or outliers compared to single models. Outliers might fool one tree, but unlikely to fool the majority.
No Hyperparameter Tuning Required
- While tuning can help, bagging is relatively robust to hyperparameters. Even default settings often work well.
Out-of-Bag Evaluation
- Free validation error estimate without splitting data or running cross-validation.
Feature Importance
- Ensemble methods like Random Forest provide reliable feature importance scores by averaging importance across all trees.
Probabilistic Predictions
- For classification, the proportion of votes can be interpreted as class probabilities, providing confidence estimates.
Limitations of Bagging
Bias Not Addressed
- Bagging reduces variance but doesn't fix bias. If your base model underfits, bagging won't help much. You need models with low bias (potentially high variance) to benefit from bagging.
Interpretability Loss
- An ensemble of 100 trees is much harder to interpret than a single tree. You lose the simplicity and explainability of individual models.
Computational Cost
- Training and storing B models requires B times the resources. For large B or complex models, this can be significant.
Memory Requirements
- Must keep all B models in memory during inference, which can be problematic for large ensembles or resource-constrained environments.
Not Ideal for Linear Models
- Bagging works best with high-variance models. Bagging low-variance models (like linear regression) provides minimal benefit since they're already stable.
Inference Time
- Making predictions requires querying all B models, which is B times slower than a single model.
When to Use Bagging
✅ Best Suited For:
High-Variance Base Models
- Decision Trees (especially deep, unpruned trees)
- K-Nearest Neighbors with small K
- Any model prone to overfitting
Complex models
- Neural Networks with many parameters
Sufficient Data
- Bootstrap Sample is ~67% of Training Set which is ~80% of whole dataset ➛ which is ~54% of overall dataset percent.
- Each model need enough data that bootstrap samples are representative, thus it have better to work with medium to large dataset
Noisy Data
- Averaging multiple models filters out noise, resulting in smoother and more accurate predictions.
Parallel Computing Available
- Can leverage multiple CPU cores
- Cloud computing environments
- High-performance computing clusters
- Works equally well for both problem types
- Particularly strong for multi-class classification
Feature Importance Needed
- Random Forest provides reliable feature importance
- Useful for feature selection and interpretation
❌ Avoid When:
Base Model Has High Bias
- Linear models on non-linear data
- Shallow trees on complex data
- Bagging won't fix underfitting
Interpretability Critical
- Medical diagnosis requiring explainable decisions
- Legal applications needing transparent reasoning
- Regulatory requirements for model interpretability
Extremely Limited Resources
- Very small datasets (n < 100)
- Severe memory constraints
- Ultra-low latency requirements (milliseconds matter)
Linear Relationships Dominate
- Simple linear regression adequate
- Data truly follows linear patterns
- Logistic regression already achieves good performance
Small Dataset
- Bootstrap Sample is ~67% of Training Set which is ~80% of whole dataset ➛ which is ~54% of overall dataset percent.
- In small datasets, the bootstrap samples become highly correlated. If models are trained on nearly identical small subsets, they will make identical errors. Bagging only works if the models are diverse; if they are all identical, you aren't "averaging out" errors—you're just repeating them.
Imbalance Dataset
- When you bootstrap a sample from a e.g 99/1 split, there is a high mathematical probability that some "bags" will contain zero examples of the minority class.
- The base models trained on these "minority-free" bags will simply learn to predict the majority class every time.
- Even if one or two models in your ensemble manage to see a few minority examples and learn to identify them, they will be outvoted by the dozens of other models that only saw the majority class.
Common Pitfalls and How to Avoid Them
| Pitfall | Problem | Solution |
|---|---|---|
| Bagging Linear Models | Minimal benefit from bagging models that are already stable | Use bagging with high-variance models (trees, neural n/w) |
| Too Few Estimators | B=10 trees won't provide enough variance reduction | Start with B=100 minimum, increase until performance plateaus |
| Overly Restricted Base Models | Very shallow trees (max_depth=3) → each model has high bias | Allow trees to grow deeper than for single-tree models |
| Ignoring Class Imbalance | Majority class dominates bootstrap samples | Use stratified sampling or balanced bagging methods |
| Not Using OOB Evaluation | Wasting data on separate validation set | Use OOB scores for model validation and selection |
| Forgetting Scaling for Some Base Models | Bagging KNN or SVM without feature scaling | Scale features appropriately for distance-based models |
| Memory Issues in Production | 500 decision trees require substantial memory | Reduce B, compress models, or use model distillation |
Common Bagging Algorithms
- Random Forest
- Extra Trees (Extremely Randomized Trees)
- Bagged Decision Trees
- General Bagging Wrapper
- Bagged SVMs
- Bagged Neural Networks
- Bagged Logistic Regression
- Bagged KNN
Scikit-learn's
BaggingClassifierandBaggingRegressorcan bag any base estimator
Advanced Techniques
| Techniques | Description | Use Case |
|---|---|---|
| Pasting | Like bagging but sampling without replacement. Each model sees a unique subset of data. | Very large datasets where bootstrap sampling is unnecessary. |
| Random Subspaces | Sample features instead of (or in addition to) samples. | High-dimensional data where feature redundancy is high. |
| Random Patches | Combine both row (sample) and column (feature) sampling. | Very high-dimensional datasets (images, text). |
| Weighted Bagging | Weight samples during bootstrap sampling based on importance or difficulty. | Imbalanced datasets or when some samples are more reliable. |
| Balanced Bagging | Ensure each bootstrap sample has balanced class distribution. | Highly imbalanced classification problems. |