Stacking (Stacked Generalization)
Sacking, it's not magic—it's a systematic way of combining multiple models where a "meta-model" learns the optimal way to blend their predictions.
I. What is Stacking?
Stacking is an ensemble learning technique where we train a meta-model to combine predictions from multiple base models. Unlike simple voting or averaging, the meta-model learns how to best combine the base models' predictions.
The key insight: Different models make different kinds of errors. A meta-model can learn which base model to trust in different situations.
The Simple Analogy
Imagine you're making an important investment decision:
- Financial Advisor A (Conservative) suggests bonds
- Financial Advisor B (Aggressive) suggests stocks
- Financial Advisor C (Balanced) suggests a mix
Instead of simply averaging their advice, you hire a senior consultant (meta-model) who knows:
- When to trust Advisor A (market volatility is high)
- When to trust Advisor B (market trends are strong)
- When to trust Advisor C (moderate conditions)
The senior consultant has learned from past decisions which advisor performs best under which conditions. That's exactly what a stacking ensemble does.
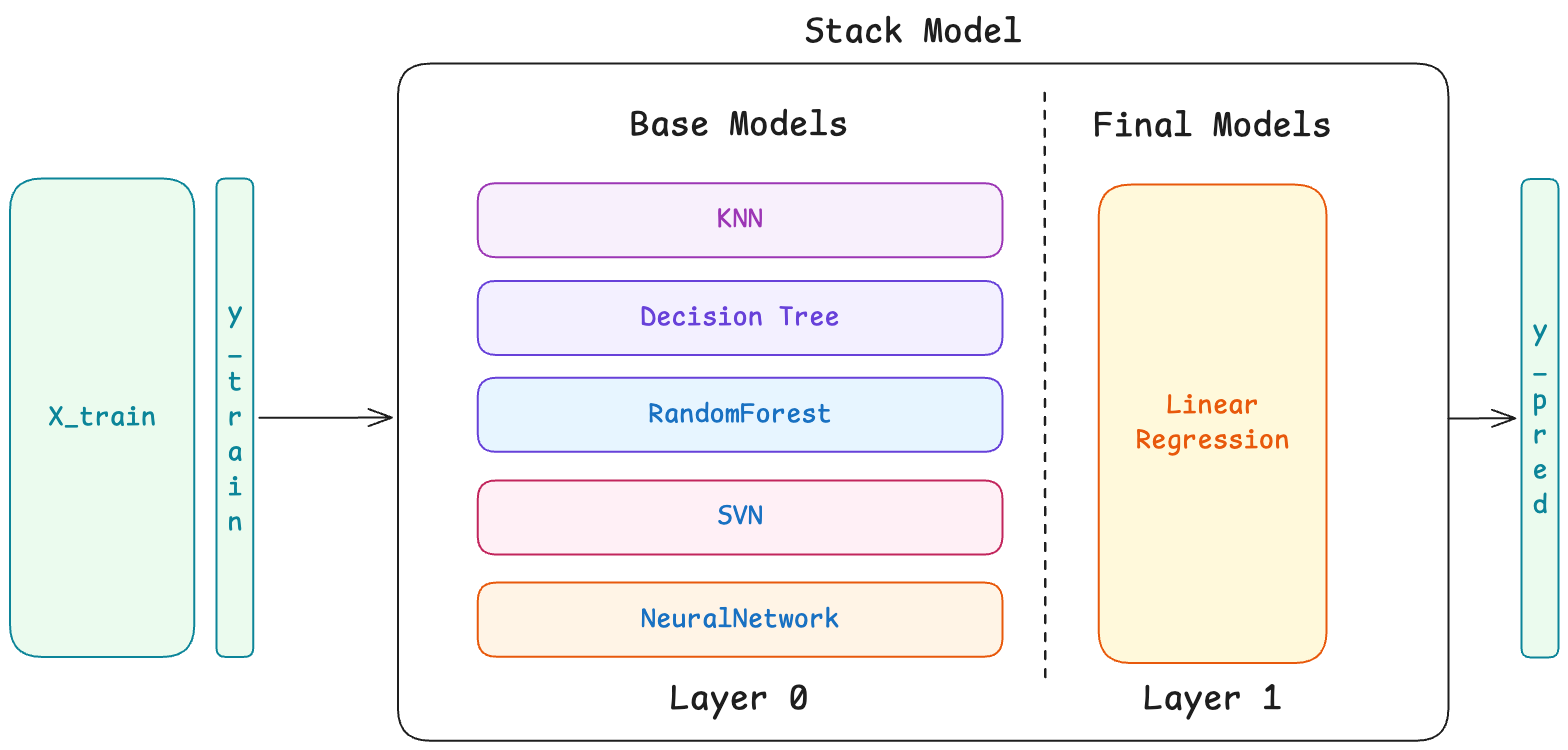
II. The Architecture: How Stacking Works?
The Two-Level Architecture
Stacking consists of two levels of models:
Level 0 (Base Models / Base Learners):
What is in Layer 0?
- Multiple diverse models (base models) like are fitted completely independently with whole dataset
and to learn from features and patterns. - Models can be of different types (e.g., linear, tree-based, distance-based, etc.).
Key Characteristics
- Each model of Layer 0 act as independent predictors and captures different patterns in the data and creates their respective prediction, which is used as an input in next later (Layer 1 / Final Model).Those fitted estimators are stored in the
stack.estimators_attribute of the stack model.
Example
- Common Models used in Layer 0 are
- Ridge Regression,
- K-Nearest Neighbors (KNN),
- Decision Trees,
- Support Vector Regressors (SVR),
- Random Forests,
- Gradient Boosting Machines, etc.
Level 1 (Meta-Model / Blender):
What is in Layer 1?
- Another separate single model which takes in combined base model predictions as input (with or without original features) to fit/train meta model.
Key Role
- Trains/fits the meta-model on the predictions of base models and
to predicts the output ( ).
Examples:
- Common final models in Layer 1 include:
- Linear Regression
- Logistic Regression
- Neural Networks
- Gradient Boosting Machines (e.g., XGBoost, CatBoost, LightGBM)
III. Types of Stacking?
Stacking is a general term, depending on the implementing, stacking can be categorized in following types.
- Blended Stacking
- Stacking with Cross-Validation
- Restacking
- Weighted Stacking
- Multilayer Stacking (Deep Stacking)
- Cascaded (Hierarchical) Stacking
IV. The Training Process: A Deep Dive
The meta-model is not trying to outsmart your base models—it's learning which model to trust in different scenarios. When Model A is confident and Model B is uncertain, maybe trust Model A. When they disagree in a specific way, maybe there's a pattern the meta-model can learn.
Each of the above types cover the training process in vivid level of depths. Start with below two and followed by others from above list
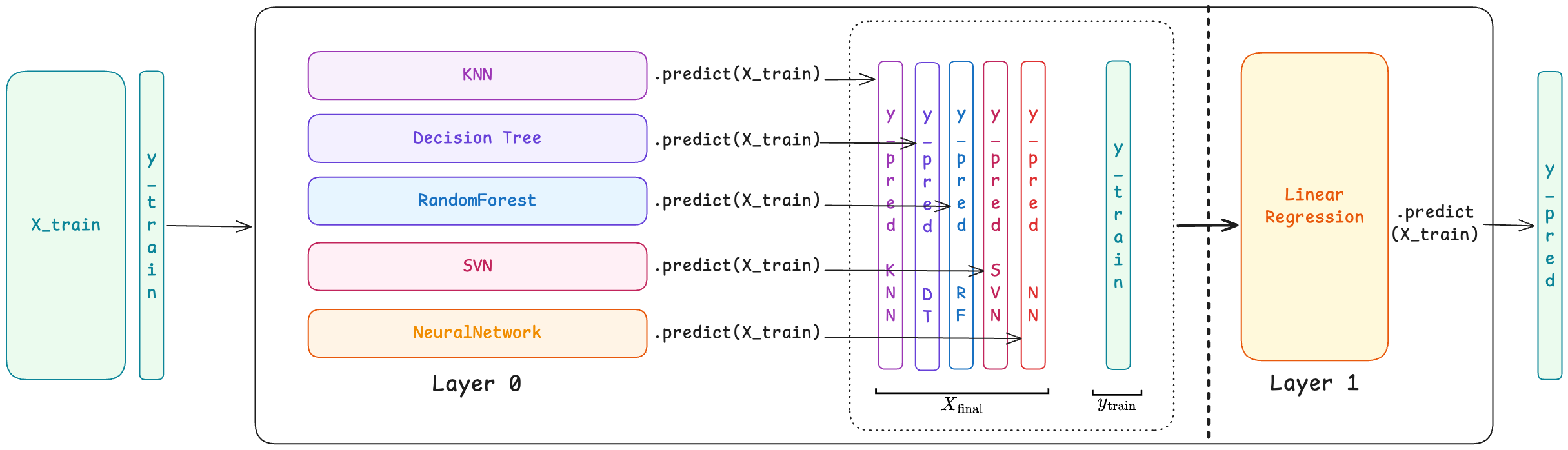
V. The Prediction Process
When we want to make predictions on test data, the process is straightforward:
graph TB
A[Test Sample] --> B1[Base Model 1
trained on full training data]
A --> B2[Base Model 2
trained on full training data]
A --> B3[Base Model 3
trained on full training data]
B1 --> C[Prediction 1: 0.65]
B2 --> D[Prediction 2: 0.71]
B3 --> E[Prediction 3: 0.58]
C --> F[Meta-Model]
D --> F
E --> F
F --> G[Final Prediction: 0.67]
style A fill:#e1f5ff
style F fill:#ffe1e1
style G fill:#c8e6c9Step-by-step:
- Retrain base models: Train each base model on the full training dataset (not just K-1 folds)
- Generate base predictions: Pass test sample through all base models
- Feed to meta-model: Use base model predictions as input to meta-model
- Get final prediction: Meta-model outputs the final prediction
Important: For test data, base models are trained on the full training set because we don't need to worry about data leakage anymore—we're not using test data for training.
VI. Choosing Base Models: The Art of Diversity
The success of stacking heavily depends on choosing diverse base models. Diverse models make different errors. When you combine them, the errors tend to cancel out.
A Good Stacking Ensemble
Here's a typical stacking setup that works well:
Base Models (Level 0):
- Random Forest: Captures non-linear patterns, handles interactions
- XGBoost: Strong sequential learner, handles missing values
- Logistic Regression with Polynomial Features: Captures linear and polynomial relationships
- Neural Network: Learns complex non-linear patterns
- K-Nearest Neighbors: Captures local patterns
Meta-Model (Level 1):
- Regularized Linear Model (Ridge or Lasso): Simple, prevents overfitting, learns optimal weights
Why This Combination Works
graph LR
A[Random Forest
Non-linear, robust] --> M[Meta-Model
Learns optimal combination]
B[XGBoost
Gradient boosting, sequential] --> M
C[Logistic Regression
Linear relationships] --> M
D[Neural Network
Complex patterns] --> M
E[KNN
Local patterns] --> M
M --> F[Best of All Worlds]
style M fill:#ffe1e1
style F fill:#c8e6c9- Random Forest might excel when features have complex interactions
- XGBoost might be best for sequential patterns
- Logistic Regression might capture global linear trends
- Neural Network might find subtle non-linear relationships
- KNN might excel for samples similar to training data
The meta-model learns: "In this region of feature space, trust the Neural Network. In that region, trust XGBoost."
VII. Implementing Stacking
VIII. Common Pitfalls and How to Avoid Them
❌ Pitfall 1: Data Leakage (The Most Critical)
Symptom: Amazing validation performance, terrible test performance.
Cause: Training meta-model on predictions from models that saw the training data.
Solution: Always use out-of-fold predictions:
# filepath: correct_oof_implementation.py
# ✅ Correct: Use cross-validation
from sklearn.model_selection import cross_val_predict
oof_predictions = cross_val_predict(
base_model, X_train, y_train,
cv=5, method='predict_proba'
)[:, 1]
# ❌ Wrong: Direct predictions on training data
wrong_predictions = base_model.fit(X_train, y_train).predict_proba(X_train)[:, 1]
❌ Pitfall 2: Using Highly Correlated Base Models
Symptom: Stacking performs no better than best base model.
Cause: All base models make similar predictions.
Example of bad combination:
# All are tree-based with similar behavior
base_models = [
RandomForestClassifier(),
ExtraTreesClassifier(),
GradientBoostingClassifier()
]
Solution: Use diverse model types:
# Mix different algorithm families
base_models = [
RandomForestClassifier(), # Tree-based
LogisticRegression(), # Linear
SVC(probability=True), # Kernel
MLPClassifier() # Neural network
]
❌ Pitfall 3: Overfitting the Meta-Model
Symptom: Meta-model training score much higher than validation score.
Cause: Meta-model is too complex or too many base models.
Solution: Use simple, regularized meta-models:
# ✅ Simple meta-model with regularization
meta_model = LogisticRegression(penalty='l2', C=1.0)
# ❌ Overly complex meta-model
meta_model = RandomForestClassifier(max_depth=20, n_estimators=500)
❌ Pitfall 4: Not Retraining Base Models on Full Data
Symptom: Test predictions are worse than expected.
Cause: Using base models trained on K-1 folds instead of full training data.
Solution: For test predictions, retrain on full data:
# filepath: proper_test_predictions.py
# For generating OOF predictions (training phase)
for train_idx, val_idx in kfold.split(X_train, y_train):
model.fit(X_train[train_idx], y_train[train_idx])
oof_pred[val_idx] = model.predict_proba(X_train[val_idx])[:, 1]
# For test predictions, retrain on FULL training data
model.fit(X_train, y_train) # Full data
test_pred = model.predict_proba(X_test)[:, 1]
❌ Pitfall 5: Inconsistent Preprocessing
Symptom: Strange predictions or errors during stacking.
Cause: Different preprocessing for base models and meta-model.
Solution: Use pipelines to ensure consistency:
# filepath: consistent_preprocessing.py
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
# Each base model with its own preprocessing
base_model_1 = Pipeline([
('scaler', StandardScaler()),
('model', SVC(probability=True))
])
base_model_2 = Pipeline([
('scaler', StandardScaler()),
('model', LogisticRegression())
])
# Use these pipelines in stacking
stacking_clf = StackingClassifier(
estimators=[
('svc', base_model_1),
('lr', base_model_2)
],
final_estimator=LogisticRegression()
)
IX. When to Use/Avoid Stacking
✅ Use Stacking When:
- You need maximum performance
- Kaggle competitions
- Critical business decisions
- High-stakes predictions
- You have diverse, strong base models
- Different algorithm families performing similarly well
- Each model captures different patterns
- You have sufficient data
- At least 10,000+ samples (more is better)
- Enough for reliable cross-validation
- Computational resources are available
- Training time is not critical
- Can afford to train multiple models multiple times
- You can validate properly
- Have held-out test set
- Can implement proper cross-validation
⚠️ Avoid Stacking When:
- Data is limited (<1,000 samples)
- Risk of overfitting increases dramatically
- Simple models might work better
- Interpretability is critical
- Stacking is a black box within a black box
- Regulators or stakeholders need to understand decisions
- Real-time predictions required
- Multiple models mean slower inference
- Consider model compression or simpler ensembles
- All base models are similar
- Stacking won't help if models make same mistakes
- Better to focus on improving diversity first
- You lack validation expertise
- Easy to make mistakes with data leakage
- Simple ensembles might be safer
Summary
Let me summarize the most important points about stacking:
🎯 Core Principles
- Stacking = Meta-Learning: A meta-model learns to optimally combine diverse base models
- Cross-validation is mandatory: Prevents data leakage and overfitting
- Diversity is key: Base models should make different errors
- Simple meta-models work best: Usually logistic/linear regression
📊 The Stacking Workflow
graph LR
A[Train Data] -->|CV Split| B[Generate OOF
Predictions]
B --> C[Train
Meta-Model]
D[Test Data] -->|Base Models
on Full Train| E[Base
Predictions]
E --> F[Meta-Model
Predicts]
C -.->|Uses Learned
Weights| F
F --> G[Final
Prediction]
style C fill:#ffe1e1
style G fill:#c8e6c9⚠️ Critical Success Factors
- Prevent data leakage: Always use out-of-fold predictions
- Choose diverse base models: Different algorithms, not just different hyperparameters
- Keep meta-model simple: Avoid overfitting the combination strategy
- Validate properly: Use held-out test set to verify performance
- Monitor correlation: If base models are highly correlated, stacking won't help
📈 Expected Performance Gains
- Typical improvement: 1-5% over best base model
- Competition-level: 0.5-2% (can make the difference between ranks)
- Diminishing returns: Adding more base models doesn't always help
- Sweet spot: 3-5 diverse base models with simple meta-model