R-Squared (The "Accuracy Score" of your Model)
R-Squared (
🎯 Part 1: The Setup - What Are We Trying to Measure?
Imagine you are trying to predict something, like how well you'll do on a test based on how many hours you studied. R-Squared is the grade we give to our prediction "rule" to see how much of the story it actually tells.
(Independent Variable): Hours studied (Dependent Variable): Exam score
You collect data from 50 students and fit a regression line:
Where:
= slope = = intercept = = predicted score
This is exactly what R-squared measures.
🧩 Part 2: The Intuition - Two Competing Model
Think of it as a competition between two models:
★ Model 1: "The Lazy Guesser" (The Mean)
- Predicting everything using just the average (
). This is our baseline. - Any "mistake" here is called Total Variation (SST) .
★ Model 2: "The Smart Predictor" (The Regression Line)**
- Predicting using our
formula. - Any "mistake" left over here is called Unexplained Variation (SSE).
"How much did we reduce our errors by being smart instead of lazy?"
🧱 Part 3: The Building Blocks
★ Block 1: Understand mean score
Imagine ignoring study hours completely. The best guess for any student’s score would be:
This is called as the mean score
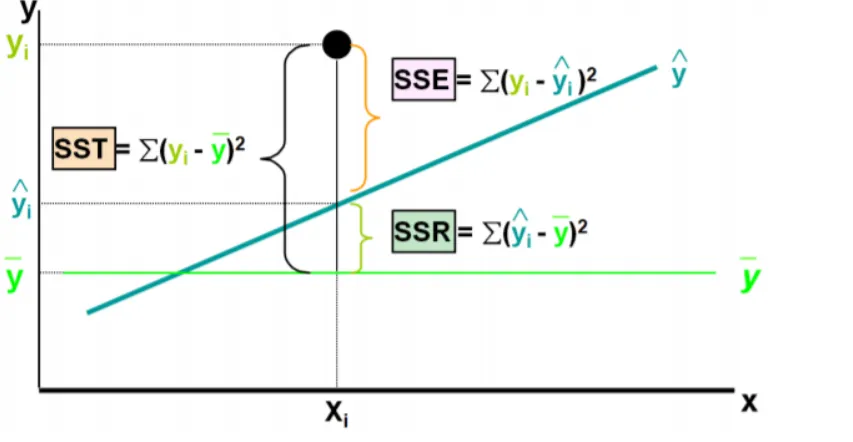
★ Block 2: The "Baseline" Model ➛ SST (Total Sum of Squares)
This measures total variability if you ignored
completely and just guessed for everyone.
Concept: Imagine you had no model at all; you would simply guess the average value
What it represents:
- The total "mystery" or uncertainty in your data
- How spread out the scores are from the mean
- The maximum possible error if you had no model
★ Block 3: The "Smart" Model ➛ SSR (Regression Sum of Squares)
This measures how much variability your regression line successfully explained by our model.
Concept: SSR represents how much "better" your regression line is at predicting the data compared to just guessing the average.
- The amount of "total mistakes" that our smart line successfully explained. i.e quantifies how much the data points (
), vary around the estimated regression line( ).
What it represents:
- The vertical distance between actual points and your predictions
- The "noise" or factors you missed
- The unexplained variance
★ Block 4: The "Leftover Mistakes" ➛ SSE (Sum of Squared Errors)
This measures the variability that your model failed to explain (the residuals).
Concept: These are the "residuals." It represents the noise or factors that your features failed to capture.
- The "mistakes" that are still there even after using our smart line. i.e quantifies how far the estimated sloped regression line,
, is from the horizontal "no relationship line," the sample mean or .
What it represents:
- The vertical distance between actual points and your predictions
- The "noise" or factors you missed
- The unexplained variance
★ The Golden Equation
These three pieces always follow this relationship:
In words: $$\boxed{\Large \text{Total Variation} = \text{Explained Variation} + \text{Unexplained Variation}}$$
🧮 Part 4: The
Now we can define R-squared in two equivalent ways:
★ Method 1: The "Success Ratio"
Interpretation: "What fraction of the total mystery did we solve?"
★ Method 2: The "Mistake Reduction Ratio"
Interpretation: "If we start with 100% mystery, how much is left over?"
📊📉 Part 5: Visual Summary Table
| Component | Formula | What it tells you |
|---|---|---|
| Total error if you just guessed the average. | ||
| How much error you "fixed" by using the model. | ||
| The error that remains after the model. |
🔢 Part 6: Worked Example
★ Given Data:
- Total Variation:
- After fitting your model, the remaining error:
★ Calculation:
🎓 Part 7: How to Interpret
The value of
- If
is small, line is a good fit. - If points lie perfectly on a line:
➛ The model explains all of the variability in the dependent variable. - If points are completely random:
➛ The model explains none of the variability in the dependent variable.
measures how tightly data hugs the regression line.
| R² Value | Meaning | Example Scenario |
|---|---|---|
| 0.90 - 1.00 | Excellent fit | Predicting height from arm length (biology) |
| 0.70 - 0.89 | Strong fit | Predicting grades from study hours |
| 0.40 - 0.69 | Moderate fit | Predicting happiness from income |
| 0.20 - 0.39 | Weak fit | Predicting stock prices from last month |
| 0.00 - 0.19 | Very weak | Predicting test scores from shoe size |
When is Low R² Acceptable?
- Social sciences: Human behavior is complex;
can be useful - Stock markets: Inherently random; even
provides value - Medical research: Many factors affect outcomes;
can save lives
🔗 Part 8: The Connection to Correlation (
For simple linear regression (one
Where
To recover
The sign rule:
- If slope (
) is positive → is positive - If slope (
) is negative → is negative
⚠️ Part 9: Important Limitations
- It doesn't prove causation: High
doesn't mean causes - It doesn't detect bias: A biased model can have high
- It doesn't validate assumptions: Check residual plots for patterns
- It rewards complexity: Adding variables always increases
(see Adjusted below)
🎯 Part 10: The Problem with
⚠️ The Flaw in
Problem:
Why? The mathematical definition of
Example of the Problem
You have a model predicting house prices with:
- Feature 1: Square footage (
) - Feature 2: Number of bedrooms (
) ✅ Improvement! - Feature 3: Homeowner's favorite color (
) 🤔 Wait...
Adding "favorite color" increased
✅ The Solution: Adjusted
Adjusted
- How it works: It only increases if the new feature improves the model's predictive power significantly more than what would be expected by random chance.
- The "Drop" Mechanism: If you add a useless feature, the
might go up by , but the penalty for adding a new variable will be larger than that tiny gain. The result? The Adjusted will actually go down.
🤔 Why Adjusted
➛ in case of Multiple linear Regression
A. It Fights Overfitting
Overfitting happens when your model learns the "noise" in your data rather than the actual "signal." By using Adjusted
B. It Guides Feature Selection
When you are deciding which features to keep:
- Add a feature.
- The Penalty: It adds a "penalty" for every new feature you add.
- If Adjusted
increases, the feature is adding value. - If Adjusted
decreases, the feature is likely noise and should be removed.
C. It Accounts for Sample Size (
The formula for Adjusted
📝 The Formula:
Where:
= number of data points = number of features (predictors) in your model
📝 Alternative Form:
📈📉 The "Gap" Test
As a rule of thumb in my lab, I always look at the gap between the two:
- Small Gap: Your features are high-quality and relevant.
- Large Gap: You have "junk" features that are inflating your
without providing real predictive power.
★ Visual Comparison:
| Scenario | Adjusted |
Verdict | |
|---|---|---|---|
| 3 features, all relevant | 0.85 | 0.84 | ✅ Good model |
| 10 features, 3 relevant | 0.87 | 0.72 | ⚠️ Overfitting! |
| 20 features, 2 relevant | 0.90 | 0.55 | 🚫 Terrible! Too complex |
📚 Part 11: Quick Summary
- R-Squared tells you what percentage of the variation in
is predictable from . - Adjusted R-Squared tells you if adding more features is actually helping or just making your model needlessly complex.
| Concept | Formula | Alternate Formula |
|---|---|---|
| R-Squared | ||
| Adjusted R-Squared | ||
| Correlation | (for simple regression) |
- Use
to see if your model explains a meaningful portion of the variation - Use
when comparing models with different numbers of features - Always visualize residuals to check if your model assumptions are valid
- Remember: A high
doesn't automatically mean a good model—context matters!