I. Entropy 》II. Joint Entropy 》III. Conditional Entropy 》IV. Mutual Information 》V. Information Gain
IV. Mutual Information (MI)
What is Mutual Information?
Mutual Information (MI) quantifies the amount of information obtained about one random variable by observing another random variable. In simpler terms, it measures how much knowing the value of variable
Conditional Entropy is the "workhorse" behind Mutual Information (MI), which is the primary metric used in your feature selection to rank how relevant a feature
Mathematical Properties
Symmetry
Unlike conditional entropy, MI is symmetric. It doesn't matter which variable you consider first.
Relationship to Entropy
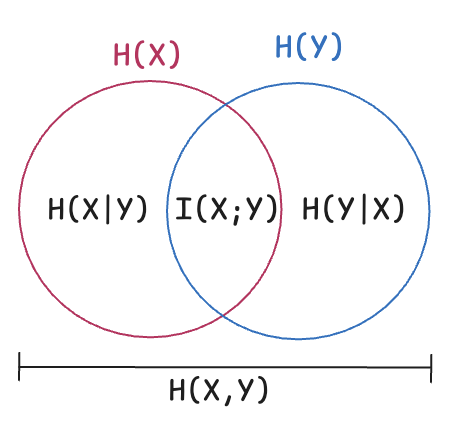
This can be visualized as a Venn diagram:
= Total uncertainty in = Total uncertainty in = Joint uncertainty - MI = The overlapping region (shared information)
Alternative Formulations
All these are equivalent:
- Via Conditional Entropy:
- Via Joint Entropy:
- Via Both Conditional Entropies:
Intuitive Interpretation
| Scenario | MI Value | Interpretation |
|---|---|---|
| No shared information | ||
| Complete information overlap | ||
| Some shared information |
V. Information Gain (IG)
Entropy tells us how impure a set of data is. Information Gain (IG) tells us how much that impurity is reduced after we split the data on a particular feature.
Information Gain (IG) is the reduction in entropy achieved by partitioning a dataset based on an attribute.
In other words, IG measures how much "information" a feature provides about the target class. A feature that creates very pure subgroups (low entropy) after a split has a high Information Gain.
Ever wonder
- How a machine learning model, like a decision tree, makes a decision?
- How does it learn to navigate complex data and make accurate predictions?
The answer lies in a powerful concept borrowed from information theory: Entropy and Information Gain (IG).
In Decision Trees (like ID3, C4.5), Information Gain is the practical application of Mutual Information. It measures the change in entropy from a "state of ignorance" to a "state of knowledge" after a split.
In other words, Information Gain is the standard metric used in decision trees to determine the best feature for a split. It measures how much "entropy" is removed from the target variable after partitioning the data based on a specific feature.
- The Mechanism: It compares the entropy of the parent node to the weighted sum of the entropies of the child nodes.
- The Strategy: High-performing models pick the feature that provides the highest Information Gain (the one that reduces the "impurity" the most).
★ Mathematical Formula and derivation
MI is calculated by subtracting the "uncertainty remaining" from the "total uncertainty":
➛ Joint Entropy The Information Gain of feature A in dataset S. and ➛ The Shannon Entropy (original uncertainty) of the target variable and respectively before the split. and ➛ The Conditional Entropy of given feature and The Conditional Entropy of given feature respectively
The remaining uncertainty after the split).
- Feature Selection (Mutual Information): As noted in your manual, MI is calculated by subtracting the "uncertainty remaining" from the "total uncertainty". In this context, we use it to find features
that result in the lowest Conditional Entropy for our target . $$I(X; Y) = H(Y) - H(Y|X)$$ - Machine Learning (Decision Trees): Algorithms like ID3 or C4.5 use Information Gain to split nodes. i.e choosing which question to ask first at a node to split data most efficiently.
Information Gain is simply the reduction in entropy $$\text{Gain} = H(\text{Parent}) - H(\text{Children}|\text{Split Condition})$$
Mutual Information vs Information Gain
| Aspect | Mutual Information | Information Gain |
|---|---|---|
| Context | General measure between any two variables | Specific to decision trees |
| Formula | ||
| Usage | Feature selection, dependency analysis | Node splitting in decision trees |
| Symmetry | Yes: |
Not necessarily (we care about reducing target entropy) |
Key Insight: Information Gain is just Mutual Information applied in the context of decision trees, where:
- SS = Target variable (class labels)
- AA = Attribute/feature used for splitting