I. Entropy 》II. Joint Entropy 》III. Conditional Entropy 》IV. Mutual Information 》V. Information Gain
III. Conditional Entropy and Weighted Entropy
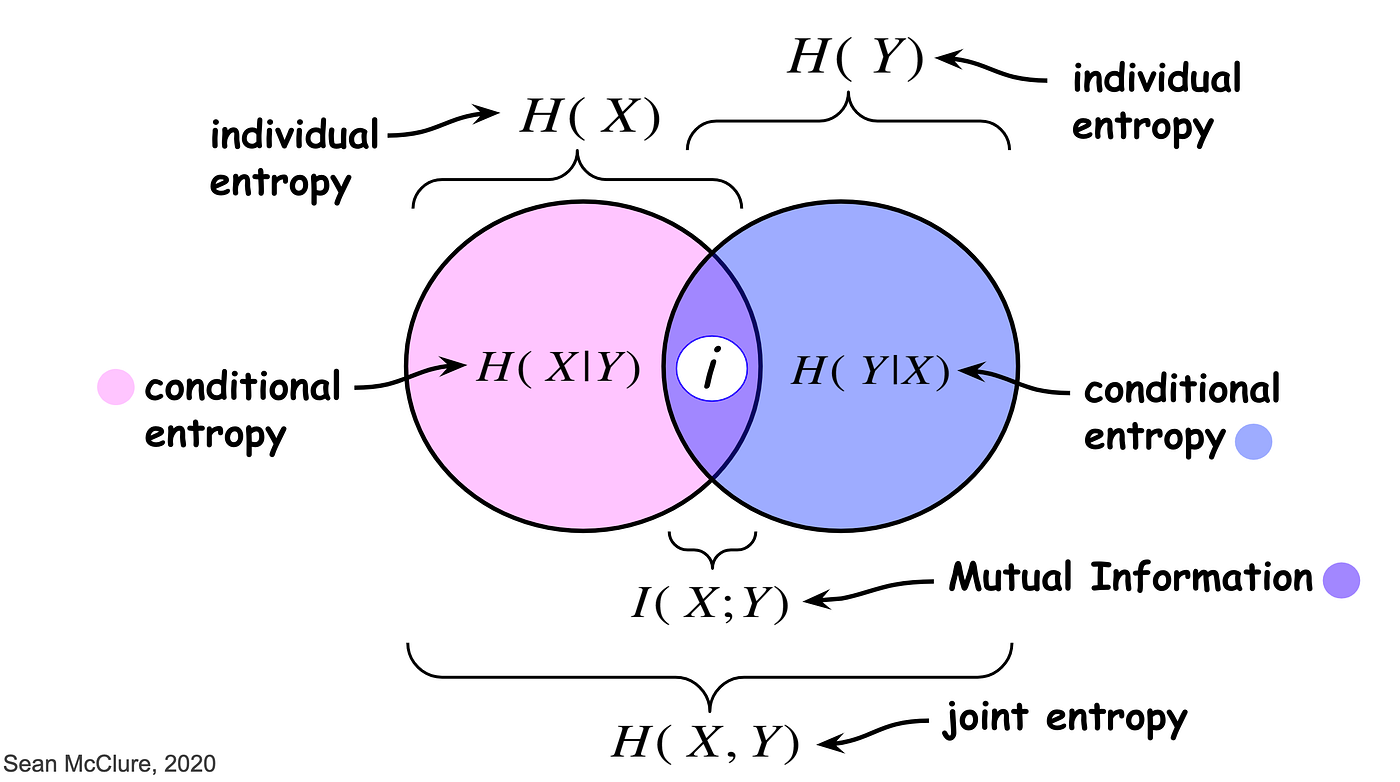
1. What is Conditional Entropy
★ Core Concept: If Shannon Entropy
★ Real-World Example:
In a Decision Tree context: "On average, how confused am I about whether someone will play golf once I know the weather?"
★ Key Property:
- One-sided relationship: We care about predicting
, and is just additional information to help us.
★ General Interpretation:
- Conditional entropy of
given is the remaining entropy of when is fixed - It represents the part of the entropy of
that is uninformative about - Also called the "noise entropy" of
with respect to
Key Properties and Boundary Cases
| Condition | Mathematical Statement | Interpretation | Practical Meaning |
|---|---|---|---|
| Reduction Property | Knowing |
Information never hurts! | |
| Perfect Predictor | No uncertainty remains; |
||
| Strong Predictor | Very low remaining uncertainty | ||
| Complete Independence | Knowing |
||
| Weak Predictor | High remaining uncertainty |
Rule of Thumb for Feature Evaluation
close to 0 → Feature is a very strong predictor of ✅ moderately low → Feature is somewhat useful in predicting ⚠️ close to → Feature is useless ❌
2. Mathematical Foundation
★ Formula
This is the conditional entropy of
Alternative (Expanded) Form:
★ Understanding the Components
and : discrete random variables : loop over all possible values that variable can take : loop over all possible values that variable can take : probability that (proportion of data where feature equals ) : conditional probability that given : joint probability that and : entropy of within the specific subset where : logarithm base 2, so entropy is measured in bits - Negative sign: makes the result non-negative (since
)
3. Interpreting Conditional Entropy Values
- Conditional entropy of Y (given X) is the remaining entropy of Y when X is fixed. Thus, conditional entropy of Y (given X) is the part of the entropy of Y that is uninformative about X. For this reason, it is also called the ‘noise entropy’ of A (with respect to B)
- Reduction:
. Knowing can only reduce or maintain the uncertainty of ; it can never increase it. - Independence: If
and are completely independent, then (knowing helps zero percent). - Perfect Correlation: If
is a deterministic function of , then (no uncertainty remains). - If
is close to 0: The feature is a very strong predictor. Most of the uncertainty is gone. - If
is close to 1: The feature is USELESS. - If
is close to : The feature is useless. Knowing didn't help you predict at all.
4. Relationship to Other Entropy Measures
★ Chain Rule for Entropy
The joint, conditional, and marginal entropies are related as follows:
In words: The joint entropy of
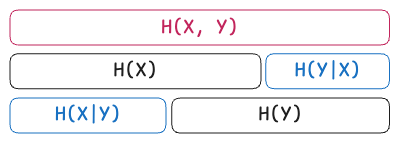
Rearranging for Conditional Entropy:
Interpretation: Conditional Entropy is the difference between the total system uncertainty (joint entropy) and the uncertainty of the known variable.
★ Derivation of the Chain Rule
Conditional Entropy accounts for relationships between variables and is mathematically linked through the Chain Rule of Information:
: The Joint Entropy (total uncertainty of the combined system) : The Shannon Entropy of the predictor variable : The Conditional Entropy (remaining uncertainty about after knowing )
5. Weighted Entropy
★ Understanding the Name "Weighted Entropy"
Weighted Entropy is another name for Conditional Entropy, but it emphasizes the computational perspective—how we actually calculate it in practice, especially when building decision trees or selecting features.
Conditional Entropy and Weighted Entropy refer to the same concept:
- Conditional Entropy is the theoretical name: "entropy of
given " - Weighted Entropy is the practical name: "weighted average of subset entropies"
They produce identical numerical results!
★ Why "Weighted"?
When we split data using feature
The Weighted Average Formula:
Breaking it down:
: The weight — the proportion of samples in subset : The entropy of the target within subset - We multiply each subset's entropy by its proportion (weight), then sum them up
Example: Unfair Split
Imagine splitting 100 patients into two groups:
- Group A (Fever): 90 patients with mixed outcomes (entropy = 0.9 bits)
- Group B (No Fever): 10 patients, all perfectly classified (entropy = 0 bits)
❌ Without weighting (WRONG):
Simple Average = (0.9 + 0.0) / 2 = 0.45 bits
This makes the split look excellent because Group B is perfect, but Group B only represents 10% of the data!
✅ With weighting (CORRECT):
Weighted Average = (0.9 × 0.9) + (0.1 × 0.0) = 0.81 bits
Interpretation: Even though Group B is perfect, the overall weighted entropy is 0.81 because 90% of the data is still messy. The split provided 0.19 bits of information gain (1.0 - 0.81), which is modest.
Comparison Table: Weighted vs Unweighted
| Scenario | Unweighted Average | Weighted Average | Why Weighted is Better |
|---|---|---|---|
| Balanced split Group A: 50 samples, entropy = 0.8 Group B: 50 samples, entropy = 0.6 |
Same result—no bias when balanced | ||
| Imbalanced split Group A: 90 samples, entropy = 0.9 Group B: 10 samples, entropy = 0.1 |
Correctly reflects that most data is still messy | ||
| Extreme imbalance Group A: 99 samples, entropy = 1.0 Group B: 1 sample, entropy = 0.0 |
Prevents tiny pure groups from dominating |
6. Step-by-Step Calculation: A Complete Example
The Dataset: Flu Diagnosis
Let's use the same flu example with a concrete dataset:
Given:
- 10 patients total
- Target Y (Flu): 6 have Flu, 4 don't
- Feature X (Fever): 7 have Fever, 3 don't
Data Table:
| Fever (X) | Flu (Y) | Count |
|---|---|---|
| Yes | Yes | 5 |
| Yes | No | 2 |
| No | Yes | 1 |
| No | No | 2 |
Step 1: Split by Feature X (Create Subsets)
- Subset 1 (Fever = Yes): 7 patients (5 with flu, 2 without)
- Subset 2 (Fever = No): 3 patients (1 with flu, 2 without)
Step 2: Calculate Entropy for Each Subset
Subset 1 Entropy (Fever = Yes):
Subset 2 Entropy (Fever = No):
Step 3: Calculate Weights (Proportions)
- Weight for Subset 1:
- Weight for Subset 2:
Step 4: Compute Weighted Average
Step 5: Interpret the Result
What does 0.879 bits mean?
- On average, after knowing if a patient has a fever, you still have 0.879 bits of uncertainty about whether they have the flu
- The feature "Fever" reduced uncertainty, but not dramatically
Calculate Information Gain:
First, we need the original total entropy:
Then:
Conclusion: Since the Information Gain is positive (but small), "Fever" is a somewhat helpful feature, but it hasn't completely resolved the uncertainty. The decision tree might need additional features to improve prediction.
7. Machine Learning Applications
1. How Decision Tree Algorithms Use Weighted Entropy
When a decision tree algorithm (like ID3, C4.5, or CART) evaluates a potential split, it follows these exact steps:
Algorithm Steps:
- Calculate weighted entropy for every possible feature
- Compare them to find which gives the lowest weighted entropy
- Choose that feature for splitting (because it gives the highest Information Gain)
- Repeat recursively for each branch until stopping criteria are met
Python Implementation
def weighted_entropy(data, feature, target):
"""
Calculate weighted entropy for a split on 'feature'
Parameters:
- data: DataFrame containing the dataset
- feature: Name of the feature column to split on
- target: Name of the target column
Returns:
- Weighted entropy (float)
"""
total_entropy = 0
total_samples = len(data)
# For each unique value of the feature
for feature_value in data[feature].unique():
# Create subset where feature == feature_value
subset = data[data[feature] == feature_value]
# Calculate weight (proportion of data in this subset)
weight = len(subset) / total_samples
# Calculate entropy of target within this subset
subset_entropy = calculate_entropy(subset[target])
# Add weighted contribution
total_entropy += weight * subset_entropy
return total_entropy
2. Feature Selection Process
Example: Comparing Multiple Features
Feature: "Patient ID is odd/even" (Bad Feature)
- Group A (Odd): 5 patients, entropy = 0.97 bits (still random)
- Group B (Even): 5 patients, entropy = 0.97 bits (still random)
Weighted Entropy = (0.5 × 0.97) + (0.5 × 0.97) = 0.97 bits
Information Gain = 0.97 - 0.97 = 0 bits
→ Feature REJECTED! ❌
Feature: "Temperature > 38°C" (Good Feature)
- Group A (High temp): 6 patients, entropy = 0.65 bits (mostly sick)
- Group B (Normal temp): 4 patients, entropy = 0.81 bits (mostly healthy)
Weighted Entropy = (0.6 × 0.65) + (0.4 × 0.81) = 0.714 bits
Information Gain = 0.97 - 0.714 = 0.256 bits
→ Feature SELECTED! ✅
The algorithm chooses "Temperature" because it has higher Information Gain.
8. Summary and Key Takeaways
1. Conditional Entropy = Weighted Entropy
- Same concept, different names
- "Conditional" emphasizes theory; "Weighted" emphasizes computation
2. The Formula
= weight (proportion of data in subset ) = entropy within subset
3. Why Weighting Matters
- Larger subsets have more influence (correctly!)
- Prevents tiny pure groups from dominating
- Essential for fair feature comparison
4. Relationship to Information Gain
- Higher gain = better feature
- Decision trees maximize information gain at each split
5. Used in Every Major Algorithm
- ID3, C4.5, CART
- Random Forest, XGBoost, Gradient Boosting
- Any tree-based method for classification
Quick Reference Guide
When evaluating a feature split:
- ✅ Calculate entropy for each subset:
- ✅ Weight by subset size:
- ✅ Sum weighted contributions:
- ✅ Compare to original entropy:
- ✅ Choose feature with highest Information Gain
Interpretation shortcuts:
→ Excellent feature! Strong predictor → Decent feature, provides some information → Useless feature, provides no information
Key Insight: Conditional Entropy = Weighted Entropy
- Conditional Entropy and Weighted Entropy are the same concept:
- Conditional Entropy is the theoretical definition:
- Weighted Entropy is the practical computation:
- Conditional Entropy is the theoretical definition:
Both give you the same result—they're just different perspectives on calculating "uncertainty remaining after knowing X."