The Output Generators: Sigmoid and Softmax
Before we can measure an error, our model has to make a prediction. Neural networks output raw numbers (often called logits). We need to transform these raw numbers into usable probabilities between 0 and 1.
This is where activation functions like Sigmoid and Softmax come in. They "squash" logits into probability distributions that we can interpret and use for classification tasks.
1. What is a Logit?
A logit is the natural logarithm of the odds ratio. It's a transformation that maps a probability value from [0, 1] to the entire real number line (-∞, +∞).
Mathematical Definition
Where:
- Probability
p: The likelihood of an event happening (e.g., 0.8 for an 80% chance), where - Odds: The ratio of the probability of an event happening to it not happening
- Logit (Log-odds): The natural logarithm of the odds, where
Analogy: Horse Betting
To understand why this transformation is useful, think about horse betting.
In horse betting, there's a commonly used term called odds. When we say the odds of horse number 5 winning are 3/8, we're actually saying that after 11 races, the horse will win 3 of them and lose 8.
Mathematically, odds are expressed as:
The odds can take any positive value:
❓Why is this useful?
Linear models (like neural networks before the final activation) produce outputs on the entire real number line. By predicting logits instead of probabilities directly, the model doesn't have to worry about constraining its output to be between 0 and 1. We can then convert the logit back to a probability using the Sigmoid function.
Deriving the Sigmoid Function from Logit
If we set the logit to a variable
By dividing the numerator and denominator by
This shows that the Sigmoid function is the inverse of the Logit function. It converts a logit back into a probability.
Context in Machine Learning
-
In Neural Networks: The input
is the weighted sum of the last layer, usually represented as: -
In Softmax: The input is a vector of logits for multiple classes:
2. Sigmoid Function
Purpose
The sigmoid function is a continuous, monotonically increasing function used to map predicted values to probabilities for Binary Classification (two choices: Yes/No, 0/1, True/False).
Formula
Where:
is the input value (logit) is Euler's number - Output: A probability value in the range
Visual Representation
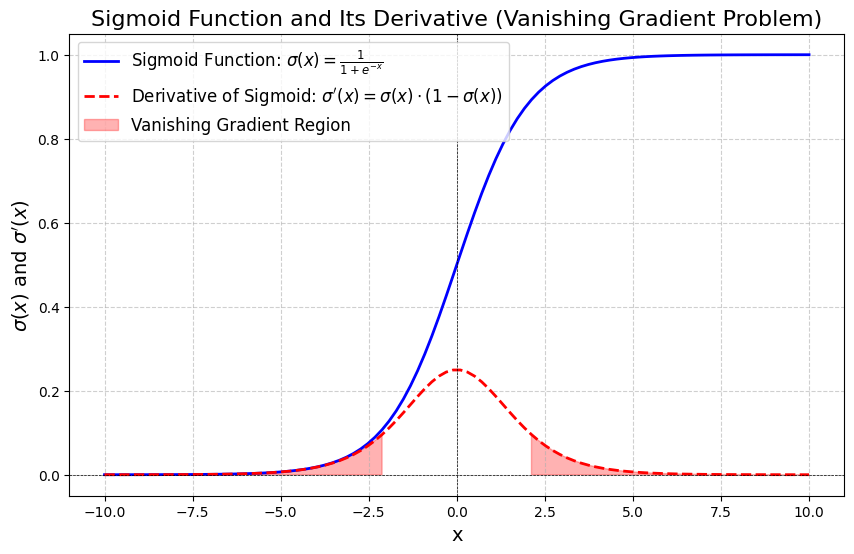
- The x-axis represents input values ranging from
to - The y-axis represents output values which always lie in
- The red shaded regions highlight areas where the derivative
is very small (close to 0). In these regions, gradients become extremely small, causing the vanishing gradient problem — the model learns very slowly or stops learning altogether.
Derivative of Sigmoid Function
The derivative is essential for backpropagation and gradient descent:
Key Properties of the Derivative:
- Maximum value:
(at ) - The derivative forms a bell curve (shown in red dotted line above)
- For large positive or negative
, the gradient vanishes (approaches 0)
Practice Problems
Calculate the sigmoid function and its derivative at various points:
| Calculation | |||
|---|---|---|---|
Properties of the Sigmoid Function
| Property | Description |
|---|---|
| Range | Output values always fall between 0 and 1, ideal for probabilities |
| Asymptotes | Approaches 0 as |
| Monotonicity | Monotonically increasing — as input increases, output increases |
| Differentiability | Fully differentiable, enabling gradient-based optimization |
| Shape | S-shaped (sigmoidal) curve with smooth, gradual transitions |
| Non-linearity | Introduces non-linearity, allowing models to learn complex patterns |
Advantages and Disadvantages
✅ Advantages
- Probabilistic Interpretation: Output is directly interpretable as a probability
- Smooth Gradient: Differentiable everywhere, enabling gradient descent
- Historical Importance: Foundational activation function in neural networks
🚫 Disadvantages
- Vanishing Gradient Problem: For extreme inputs (
), gradients become extremely small, slowing or halting learning - Not Zero-Centered: Outputs are always positive
, which can complicate optimization - Computational Cost: Exponential calculations are slower than simpler functions like ReLU
- Output Saturation: Model can become overconfident with saturated outputs near 0 or 1
Use Cases
- Binary Classification: The standard choice for the output layer when predicting two classes
- Logistic Regression: The core function used in logistic regression models
- Hidden Layers (Historical): Used in early neural networks, now largely replaced by ReLU
- Financial Example: Predicting if the S&P 500 will close Green (1) or Red (0) today. If Sigmoid outputs 0.85, the model is 85% confident the market closes green.
3. Softmax Function
Purpose
Softmax is the generalization of Sigmoid for Multi-class Classification (three or more mutually exclusive choices). It converts a vector of raw scores (logits) into a probability distribution.
Formula
Where:
: The logit (raw score) for class : Total number of classes : Exponentiation of the logit for class : Sum of all exponentiated logits (normalization term) - Output:
represents the probability of class , where
Visual Representation
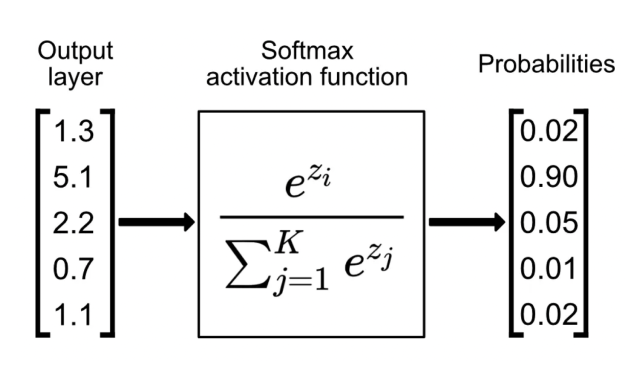
Recipe of Softmax
The Softmax function operates in three steps:
-
Input: Takes a vector
of real numbers (logits) from the final layer -
Exponentiation: Each element is exponentiated using
(Euler's number) This ensures all values become positive and amplifies differences
-
Normalization: Divide each exponentiated value by the sum of all exponentiated values
This guarantees the outputs sum to 1 (a valid probability distribution)
Derivative of Softmax
The derivative of Softmax is more complex due to its dependency on all inputs. For class
When combined with Cross-Entropy Loss, the gradient simplifies elegantly to:
Where
Properties of Softmax
| Property | Description |
|---|---|
| Normalization | Converts logits into a probability distribution where |
| Exponentiation | Amplifies larger values, making the model's confidence more pronounced |
| Differentiability | Fully differentiable, enabling gradient-based optimization |
| Output Range | All outputs lie between 0 and 1 |
| Mutual Exclusivity | Designed for problems where each sample belongs to exactly one class |
| Interpretability | Transforms raw outputs into probabilities that are easy to understand |
Advantages and Disadvantages
✅ Advantages
- Probability Distribution: Provides a well-defined probability distribution for each class
- Interpretability: Probabilities are easier to understand than raw logits
- Numerical Stability: Works well with Cross-Entropy Loss for stable training
- Multi-class Support: Natural extension of Sigmoid to multiple classes
❌ Disadvantages
- Overconfidence: Tends to produce extremely confident predictions even for uncertain inputs
- Sensitivity to Outliers: Small variations in logits can cause large shifts in probabilities
- Softmax Bottleneck: Limited ability to model complex relationships between output classes
- Poor Calibration: Predicted probabilities often don't align with true likelihoods
- Gradient Saturation: Can cause vanishing gradients when one class probability dominates
- Not Suitable for Multi-Label: Assumes mutually exclusive classes; for multi-label problems, use multiple independent Sigmoid functions
Use Cases
- Image Classification: Classifying images into categories (e.g., cat, dog, bird)
- Sentiment Analysis: Classifying text sentiment (positive, negative, neutral)
- Language Modeling: Predicting the next word from a vocabulary
- Recommendation Systems: Ranking and selecting items from multiple options
Financial Example: Predicting which ETF will perform best this year: VOO, QQQM, or SCHD. Softmax might output
4. Sigmoid vs. Softmax: Key Differences

Sigmoid receives a single input and outputs a single probability representing class 1. The probability of class 0 is simply
. Softmax is vectorized — it takes a vector with
entries (one for each class) and outputs another vector where each component represents the probability of belonging to that class. All probabilities sum to 1.
| Feature | Sigmoid | Softmax |
|---|---|---|
| Use Case | Binary Classification (2 classes) | Multi-class Classification (K > 2 classes) |
| Input | Single scalar |
Vector |
| Output | Single probability |
Probability distribution |
| Formula | ||
| Derivative | ||
| Interpretation | Probability of positive class | Probability distribution over all classes |
| Classes | Two mutually exclusive classes | Multiple mutually exclusive classes |
| Multi-label | Can be used independently for each label | Not suitable; use multiple Sigmoid instead |
5. Questions and Answers
1. How is the sigmoid function used in neural networks?
In neural networks, the sigmoid function is used as an activation function. It takes the weighted sum of inputs and transforms it into an output between 0 and 1. This introduces non-linearity, allowing the network to learn complex patterns. However, it's mostly used in the output layer for binary classification; ReLU is preferred for hidden layers.
2. What are the mathematical properties of the sigmoid function?
The sigmoid function:
- Outputs values between 0 and 1
- Is differentiable everywhere
- Is monotonically increasing
- Has an S-shaped curve introducing non-linearity
- Supports gradient-based learning
- Can suffer from vanishing gradients for extreme inputs
3. Why is the sigmoid function important in logistic regression?
The sigmoid function is crucial in logistic regression because it converts the linear combination of input features
4. How does the sigmoid function compare to other activation functions?
| Function | Pros | Cons | Best Use |
|---|---|---|---|
| Sigmoid | Probabilistic output, smooth gradient | Vanishing gradients, not zero-centered, slow | Output layer (binary) |
| ReLU | Fast, no vanishing gradient (for |
Dead neurons for |
Hidden layers |
| Tanh | Zero-centered, stronger gradients than Sigmoid | Still suffers from vanishing gradients | Hidden layers (less common now) |
| Softmax | Multi-class probabilities, interpretable | Not for multi-label, sensitive to outliers | Output layer (multi-class) |
5. What is the vanishing gradient problem?
The vanishing gradient problem occurs when gradients become extremely small during backpropagation, causing weights to update very slowly or not at all. This happens in Sigmoid when:
- Input
is very large ( ): , - Input
is very negative ( ): ,
6. Why use Softmax in the last layer?
The Softmax activation function is typically used in the final layer of a classification neural network because:
- It transforms raw outputs into interpretable probabilities
- It ensures outputs are mutually exclusive (sum to 1), suitable for problems where each sample belongs to exactly one class
- It works seamlessly with Cross-Entropy Loss, which measures the difference between predicted and actual probabilities
- The combined gradient (Softmax + Cross-Entropy) is simple:
7. Can I use multiple Sigmoid functions instead of Softmax?
Yes, but only for multi-label classification where an input can belong to multiple classes simultaneously (e.g., an image can contain both "cat" and "dog"). Each Sigmoid acts as an independent binary classifier for each class. For multi-class classification where classes are mutually exclusive, use Softmax.
8. How do you handle numerical instability in Softmax?
The exponential function in Softmax can cause overflow for large logits. The solution is to subtract the maximum logit before computing:
This is mathematically equivalent but numerically stable. Modern deep learning frameworks handle this automatically.
6. Summary
| Concept | Sigmoid | Softmax |
|---|---|---|
| Type | Binary activation | Multi-class activation |
| Classes | 2 (mutually exclusive) | K (mutually exclusive) |
| Output | Single probability | Probability distribution |
| Formula | ||
| Range | Each output in |
|
| Use in ML | Binary classification output | Multi-class classification output |
| Paired with | Binary Cross-Entropy Loss | Categorical Cross-Entropy Loss |
Key Takeaway: Use Sigmoid for binary problems (two classes). Use Softmax for multi-class problems where each input belongs to exactly one class. For multi-label problems, use multiple independent Sigmoid functions.